This week I received a question about Storage DRS. The question was if it was possible to have a VM with multiple disks in different datastore clusters? It’s not uncommon to have set ups like these so I figured it would be smart to document it. The answer is yes that is supported. You can create a virtual machine with a system disk on a raid-5 backed datastore cluster and a data disk on a raid-10 backed datastore cluster. If Storage DRS sees the need to migrate either of the disks to a different datastore it will make the recommendation to do so.
5
vSphere 5 Coverage
I just read Eric’s article about all the topics he covered around vSphere 5 over the last couple of weeks and as I just published the last article I had prepared I figured it would make sense to post something similar. (Great job by the way Eric, I always enjoy reading your articles and watching your videos!) Although I did hit roughly 10.000 unique views on average per day the first week after the launch and still 7000 a day currently I have the feeling that many were focused on the licensing changes rather then all the new and exciting features that were coming up, but now that the dust has somewhat settled it makes sense to re-emphasize them. Over the last 6 months I have been working with vSphere 5 and explored these features, my focus for most of those 6 months was to complete the book but of course I wrote a large amount of articles along the way, many of which ended up in the book in some shape or form. This is the list of articles I published. If you feel there is anything that I left out that should have been covered let me know and I will try to dive in to it. I can’t make any promises though as with VMworld coming up my time is limited.
- Live Blog: Raising The Bar, Part V
- 5 is the magic number
- Hot of the press: vSphere 5.0 Clustering Technical Deepdive
- vSphere 5.0: Storage DRS introduction
- vSphere 5.0: What has changed for VMFS?
- vSphere 5.0: Storage vMotion and the Mirror Driver
- Punch Zeros
- Storage DRS interoperability
- vSphere 5.0: UNMAP (vaai feature)
- vSphere 5.0: ESXCLI
- ESXi 5: Suppressing the local/remote shell warning
- Testing VM Monitoring with vSphere 5.0
- What’s new?
- vSphere 5:0 vMotion Enhancements
- vSphere 5.0: vMotion enhancement, tiny but very welcome!
- ESXi 5.0 and Scripted Installs
- vSphere 5.0: Storage initiatives
- Scale Up/Out and impact of vRAM?!? (part 2)
- HA Architecture Series – FDM (1/5)
- HA Architecture Series – Primary nodes? (2/5)
- HA Architecture Series – Datastore Heartbeating (3/5)
- HA Architecture Series – Restarting VMs (4/5)
- HA Architecture Series – Advanced Settings (5/5)
- VMFS-5 LUN Sizing
- vSphere 5.0 HA: Changes in admission control
- vSphere 5 – Metro vMotion
- SDRS and Auto-Tiering solutions – The Injector
Once again if there it something you feel I should be covering let me know and I’ll try to dig in to it. Preferably something that none of the other blogs have published of course.
SDRS and Auto-Tiering solutions – The Injector
A couple of weeks ago I wrote an article about Storage DRS (hereafter SDRS) interoperability and I mentioned that using SDRS with Auto-Tiering solutions should work… Now the truth is slightly different, however as I noticed some people started throwing huge exclamation marks around SDRS I wanted to make a statement. Many have discussed this and made comments around why SDRS would not be supported with auto-tiering solutions and I noticed the common idea is that SDRS would not be supported with them as it could initiate a migration to a different datastore and as such “reset” the tiered VM back to default. Although this is correct there is a different reason why VMware recommends to follow the guidelines provided by the Storage Vendor. The guideline by the way is to use Space Balancing but not enable I/O metric. Those who were part of the beta or have read the documentation, or our book might recall this when creating datastore clusters select datastores which have similar performance characteristics. In other words do not mix an SSD backed datastore with a SATA backed datastore, however mixing SATA with SAS is okay. Before we will explain why lets repeat the basics around SDRS:
SDRS allows the aggregation of multiple datastores into a single object called a datastore cluster. SDRS will make recommendations to balance virtual machines or disks based on I/O and space utilization and during virtual machine or virtual disk provisioning make recommendations for placement. SDRS can be set in fully automated or manual mode. In manual mode SDRS will only make recommendations, in fully automated mode these recommendations will be applied by SDRS as well. When balancing recommendations are applied Storage DRS is used to move the virtual machine.
So what about Auto-Tiering solutions? Auto-tiering solutions move “blocks” around based hotspots. Yes, again, when SvMotion would migrate the virtual machine or virtual disk this process would be reset. In other words the full disk will land on the same tier and the array will need to decide at some point what belongs where… but is this an issue? In my opinion it probably isn’t but it will depend on why SDRS decides to move the virtual machine as it might lead to a temporary decrease in performance for specific chunks of data within the VM. As auto-tiering solutions help preventing performance issues by moving blocks around you might not want to have SDRS making performance recommendations but why… what is the technical reason for this?
As stated SDRS uses I/O and space utilization for balancing… Space makes sense I guess but what about I/O… what does SDRS use, how does it know where to place a virtual machine or disk? Many people seem to be under the impression that SDRS simply uses average latency but would that work in a greenfield deployment where no virtual machines are deployed yet? It wouldn’t and it would also not say much about the performance capabilities of the datastore. No in order to ensure the correct datastore is selected SDRS needs to know what the datastore is capable off, it will need to characterize the datastore and in order to do so it uses Storage IO Control (hereafter SIOC), more specifically what we call “the injector”. The injector is part of SIOC and is a mechanism which is used to characterize each of the datastore by injecting random (read) I/O. Before you get worried, the injector only injects I/O when the datastore is idle. Even when the injector is busy and it notices other activity on the datastore it will back down and retry later. Now in order to characterize the datastore the injector uses different amount of outstanding I/Os and measures the latency for these I/Os. For example it starts with 1 outstanding I/O and gets a response within 3 miliseconds. When 3 outstanding I/Os are used the average latency for these I/Os is 3.8 miliseconds. With 5 I/Os the average latency is 4.3 and so on and so forth. For each device the outcome can be plotted as show in the below screenshot and the slope of the graph indicates the performance capabilities of the datastore. The steeper the line the lower the performance capabilities. The graphs shows the test where a multitude of datastores are characterized each being backed by a different number of spindles. As clearly shown there is a relationship between the steepness and the number of spindles used.
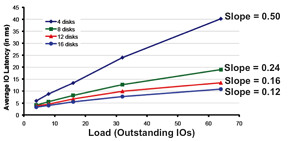
So why does SDRS care? Well in order to ensure the correct recommendations are made each of the datastores will be characterized in other words a datastore backed by 16 spindles will be a more logical choice than a datastore with 4 spindles. So what is the problem with Auto-Tiering solutions? Well think about it for a second… when a datastore has many hotspots an auto-tiering solution will move chunks around. Although this is great for the virtual machine it also means that when the injector characterizes the datastore it could potentially read from the SSD backed chunks or the SATA backed chunks and this will lead to unexpected results in terms of average latency and as you can imagine this will be confusing to SDRS and possibly lead to incorrect recommendations. Now, this is typically one of those scenarios which requires extensive testing and hence the reason VMware refers to the storage vendor for their recommendation around using SDRS in combination with auto-tiering solutions. My opinion: Use SDRS Space Balancing as this will help preventing downtime related to “out of space” scenarios and also help speeding up the provisioning process. On top of that you will get Datastore Maintenance Mode and Affinity Rules.
vSphere 5 – Metro vMotion
I received a question last week about higher latency thresholds for vMotion… A rumor was floating around that vMotion would support RTT latency up to 10 miliseconds instead of 5. (RTT=Round Trip Time) Well this is partially true. With vSphere 5.0 Enterprise Plus this is true. With any of the versions below Enterprise Plus the supported limit is 5 miliseconds RTT. Is there a technical reason for this?
There’s a new component that is part of vMotion which is only enabled with Enterprise Plus and that components is what we call ‘Metro vMotion’. This feature enables you to safely vMotion a virtual machine across a link of up to 10 miliseconds RTT. The technique used is common practice in networking and a bit more in-depth described here.
In the case of vMotion the standard socket buffer size is around 0.5MB. Assuming a 1GbE network (or 125MBps) then bandwidth delay product dictates that we could support roughly 5ms RTT delay without a noticeable bandwidth impact. With the “Metro vMotion” feature, we’ll dynamically resize the socket buffers based on the observed RTT over the vMotion network. So, if you have 10ms delay, the socket buffers will be resized to 1.25MB, allowing full 125MBps throughput. Without “Metro vMotion”, over the same 10ms link, you would get around 50MBps throughput.
Is that cool or what?
vSphere 5.0 HA: Changes in admission control
I just wanted to point out a couple of changes for HA in vSphere 5.0 with regards to admission control. Although they might seem minor they are important to keep in mind when redesigning your environment. Lets just discuss each of the admission control policies and list the changes underneath.
- Host failures cluster tolerates
Still uses the slot algorithm. Major change here is that you can have a value larger than 4 hosts. The 4 host limit was imposed by the Primary/Secondary node concept. As this constraint has been lifted it is now possible to select a value up to 31. So in the case of a 16 host cluster you can set the value to 15. (Yes you could even set it to 31 as the UI doesn’t limit you but that wouldn’t make sense would it…) Another change is the default slotsize for CPU. The default slotsize used to be 256MHz. This has been decreased to 32MHz. - Percentage as cluster resources reserved
This admission control policy has been overhauled and it is now possible to select a percentage for both CPU and Memory separately. In other words you can set CPU to 30% and Memory to 25%. The algorithm hasn’t changed and this is still my preferred admission control policy! - Specify Failover host
Allows you to select multiple hosts instead of just 1. So for instance in an 8 host cluster you can specify two as designated failover hosts. These hosts will not be used during normal operations, keep this in mind!
For more details on admission control I would like to refer to the HA deepdive (not updated to 5.0 yet) or my book on vSphere 5.0 Clustering which contains many examples of how to correctly set the percentage for instance.