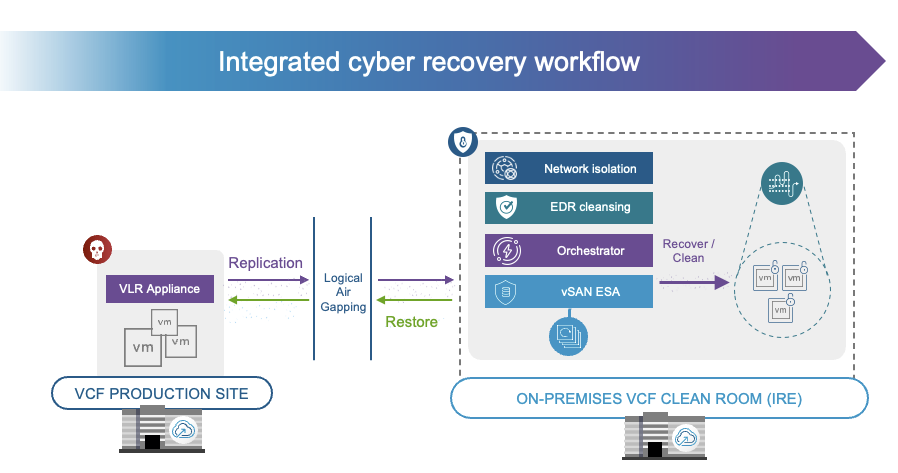
Just recorded a new demo for VCF 9.1 Protection and Recovery, or VMware Live Recovery as it was called previously. In this demo I show the recovery process after a ransomware attack! I just love how easy it is with this platform, and how it includes integration with either Carbon Black or CrowdStrike.