A couple of weeks ago I wrote an article about Storage DRS (hereafter SDRS) interoperability and I mentioned that using SDRS with Auto-Tiering solutions should work… Now the truth is slightly different, however as I noticed some people started throwing huge exclamation marks around SDRS I wanted to make a statement. Many have discussed this and made comments around why SDRS would not be supported with auto-tiering solutions and I noticed the common idea is that SDRS would not be supported with them as it could initiate a migration to a different datastore and as such “reset” the tiered VM back to default. Although this is correct there is a different reason why VMware recommends to follow the guidelines provided by the Storage Vendor. The guideline by the way is to use Space Balancing but not enable I/O metric. Those who were part of the beta or have read the documentation, or our book might recall this when creating datastore clusters select datastores which have similar performance characteristics. In other words do not mix an SSD backed datastore with a SATA backed datastore, however mixing SATA with SAS is okay. Before we will explain why lets repeat the basics around SDRS:
SDRS allows the aggregation of multiple datastores into a single object called a datastore cluster. SDRS will make recommendations to balance virtual machines or disks based on I/O and space utilization and during virtual machine or virtual disk provisioning make recommendations for placement. SDRS can be set in fully automated or manual mode. In manual mode SDRS will only make recommendations, in fully automated mode these recommendations will be applied by SDRS as well. When balancing recommendations are applied Storage DRS is used to move the virtual machine.
So what about Auto-Tiering solutions? Auto-tiering solutions move “blocks” around based hotspots. Yes, again, when SvMotion would migrate the virtual machine or virtual disk this process would be reset. In other words the full disk will land on the same tier and the array will need to decide at some point what belongs where… but is this an issue? In my opinion it probably isn’t but it will depend on why SDRS decides to move the virtual machine as it might lead to a temporary decrease in performance for specific chunks of data within the VM. As auto-tiering solutions help preventing performance issues by moving blocks around you might not want to have SDRS making performance recommendations but why… what is the technical reason for this?
As stated SDRS uses I/O and space utilization for balancing… Space makes sense I guess but what about I/O… what does SDRS use, how does it know where to place a virtual machine or disk? Many people seem to be under the impression that SDRS simply uses average latency but would that work in a greenfield deployment where no virtual machines are deployed yet? It wouldn’t and it would also not say much about the performance capabilities of the datastore. No in order to ensure the correct datastore is selected SDRS needs to know what the datastore is capable off, it will need to characterize the datastore and in order to do so it uses Storage IO Control (hereafter SIOC), more specifically what we call “the injector”. The injector is part of SIOC and is a mechanism which is used to characterize each of the datastore by injecting random (read) I/O. Before you get worried, the injector only injects I/O when the datastore is idle. Even when the injector is busy and it notices other activity on the datastore it will back down and retry later. Now in order to characterize the datastore the injector uses different amount of outstanding I/Os and measures the latency for these I/Os. For example it starts with 1 outstanding I/O and gets a response within 3 miliseconds. When 3 outstanding I/Os are used the average latency for these I/Os is 3.8 miliseconds. With 5 I/Os the average latency is 4.3 and so on and so forth. For each device the outcome can be plotted as show in the below screenshot and the slope of the graph indicates the performance capabilities of the datastore. The steeper the line the lower the performance capabilities. The graphs shows the test where a multitude of datastores are characterized each being backed by a different number of spindles. As clearly shown there is a relationship between the steepness and the number of spindles used.
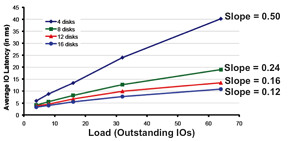
So why does SDRS care? Well in order to ensure the correct recommendations are made each of the datastores will be characterized in other words a datastore backed by 16 spindles will be a more logical choice than a datastore with 4 spindles. So what is the problem with Auto-Tiering solutions? Well think about it for a second… when a datastore has many hotspots an auto-tiering solution will move chunks around. Although this is great for the virtual machine it also means that when the injector characterizes the datastore it could potentially read from the SSD backed chunks or the SATA backed chunks and this will lead to unexpected results in terms of average latency and as you can imagine this will be confusing to SDRS and possibly lead to incorrect recommendations. Now, this is typically one of those scenarios which requires extensive testing and hence the reason VMware refers to the storage vendor for their recommendation around using SDRS in combination with auto-tiering solutions. My opinion: Use SDRS Space Balancing as this will help preventing downtime related to “out of space” scenarios and also help speeding up the provisioning process. On top of that you will get Datastore Maintenance Mode and Affinity Rules.
It’s good to see everyone instrested in SDRS but I think one of the huge benefits is for the SMB. I think more than ever a SMB doesn’t have to pay for the Tier I storage array and can just use the features within vSphere.
Will there be VAII api for SRDS in the future?
-Dwayne
@dlink7
Not sure what yoy mean with vaai api?
Great article, Duncan. Knowing how it works under the covers makes the feature that much more impressive to me. SRDS + tiering is going to be a fun new design/management element going forward, thanks for the info!
More details can be found in the “basil” acadamic paper by the way,
Good post, Duncan, thanks for the additional clarity behind the recommendations. This will definitely be a key design point in many, many implementations.
Good post Duncan – The injector information is very helpful.
Does this also mean the injector will be disrupted by datastores on LUNs that share spindles with other LUNs, in the same way that SIOC is?
No it will not. In those cases it will characterize the load based on what the capabilities of those LUNs are in terms of I/O. The fact that load is sharing those spindles shouldn’t matter for the actual algorithm.
Thanks Duncan, thants good to know. I very much want to use these features, but won’t have dedicated spindles.
Great post. This is very informative and I did not know about the injector. It will be interesting to see how the functionality of SDRS improves related to autotiering as the API’s mature. Seemingly a good target for a future API so that vSphere understands tiering capability of the array (a complex feat no doubt).
Great article, and great website. It is nice to be able to find a clear explanation of how these two technoliges may or may not work well together.
This is great information on the design strategy behind auto-tiering and SDRS. In the case of EMC VMAX, they state clearly the recommendation to disable the io metric and enable space balancing. However, what I can’t seem to find is an in-depth discussion on how auto-tiering and profile-driven storage should be designed together. It would be great if you could write on that sometime too.