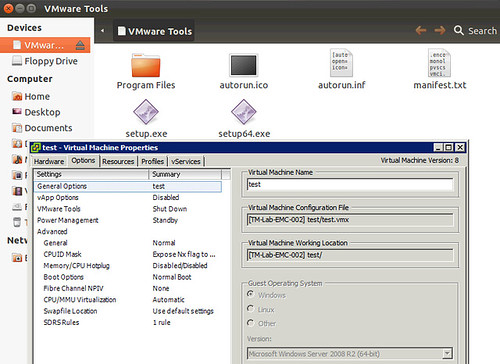
I had a discussion yesterday about why one would care about changing the “OS” type for a VM when it is upgraded, or even during the provisioning of a VM. I guess the obvious one is that a VM is “customized / optimized” based on this information from a hardware perspective. Another one that many people don’t realize is that when you initiate a VMware Tools install or Upgrade the information provided in the “Guest Operating System” (VM properties, Options, General Options) is used to mount the correct file. As you can see in the screenshot below, I selected “Windows 2008” but actually installed Ubuntu, when I wanted to install VMware Tools the Windows binaries popped up. So make sure you update this info correctly,