![]() Last week I had the pleasure of catching up with Tintri. It has been a while since I spoke with them, but I have been following them from the very start. I met up with them in Mountain View a couple of times when it was just a couple of guys on a rather empty floor with a solution that sounded really promising. Tintri’s big thing is simplicity if you ask me. Super simple to setup, really easy to manage, and providing VM granular controls for about everything you can imagine. The solution comes in the form of a hybrid storage device (disks and flash) which is served up to the hypervisor as an NFS mount.
Last week I had the pleasure of catching up with Tintri. It has been a while since I spoke with them, but I have been following them from the very start. I met up with them in Mountain View a couple of times when it was just a couple of guys on a rather empty floor with a solution that sounded really promising. Tintri’s big thing is simplicity if you ask me. Super simple to setup, really easy to manage, and providing VM granular controls for about everything you can imagine. The solution comes in the form of a hybrid storage device (disks and flash) which is served up to the hypervisor as an NFS mount.
Today Tintri announces that they will be offering an all-flash system next to their hybrid systems. When talking to Kieran he made it clear that the all-flash system would probably be only for a subset of their customers. The key reason for this being that the hybrid solution already brings great performance and is at a much lower cost of course. The new all-flash model is named VMstore T5000 and comes in two variants: T5060 and T5080. The T5060 can hold up to 2500 VMs and around 36TB with dedupe and compression. For the T5080 that is 5000 VMs and around 73TB. Both delivered in a 2U form factor by the way. The expected use case for the all flash systems is large persistent desktops and multi TB high performance databases. Key thing here is of course not jus the number of IOPS it can drive, but the consistent low latency it can deliver.
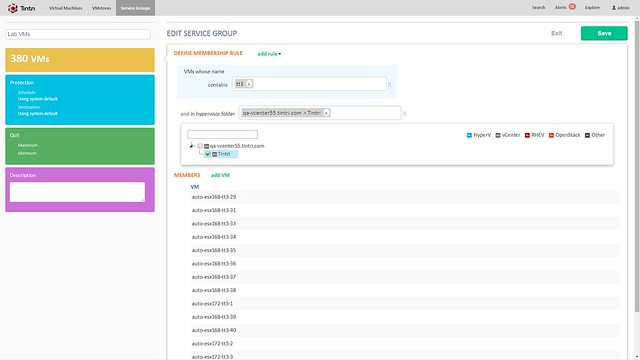
Besides the hardware, there is also a software refresh. Tintri OS 4.0 and Global Center 2.1 are being announced. Tintri OS 4.0 is what is sitting on the VMstore storage systems and Global Center is their central management solution. With the 2.1 release Global Center now supports up to 100.000 VMs. It allows you to centrally manage both Tintri’s hybrid and all-flash systems from one UI and smart things like informing you when a VM is provisioned to the wrong storage system (hybrid but performance wise requires all-flash for instance). Not just inform you, but it also has the ability to migrate the VM from storage system to storage system. Note that during the migration all aspects that were associated with it (QoS, Replication etc) is kept. (Not unlike Storage DRS, but in this case the solution is aware of all that happens on the storage system) What I liked personally about Global Center is the performance views / health views. It is very easy to see what the state of your environment is, where latency is coming from etc. Also, if you need to configure things like QoS, replication or snapshotting for multiple VMs you can do this from the Global Center console by simply grouping them as show in the screenshot below.
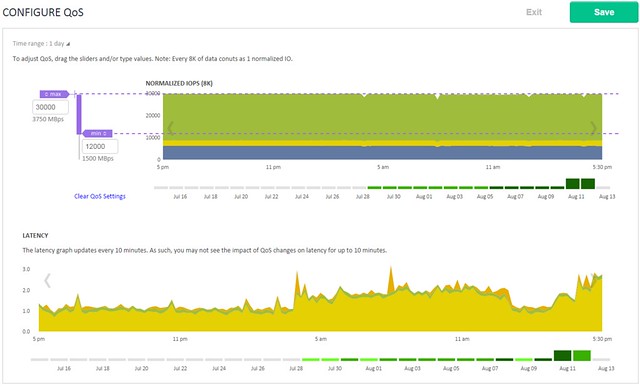
Tintri QoS was demoed during the call, and I found this also particularly interesting as it allows you to define QoS on a VM (or VMDK) granular level. When you do things like specifying an IOPS limit it is good to know that Tintri normalizes the IOPS based on the size of the IO. Simply said, all IO of 8KB or lower becomes 1 normalized IOPS, an IO which is 16KB will be 2 normalized IOPS etc. This to ensure fairness in environments (this will be almost every environment) where IO sizes greatly vary. Those whom have ever tried to profile their workloads will know why this is important. What I’ve always like about Tintri is their monitoring things like latency for instance how they split that up in hypervisor, network and storage is very useful. They have done an excellent job again for QoS management.
Last but not least Tintri introduces Tintri VMstack. Basically their converged offering where Compute + Storage + Hypervisor is bundled and delivered as a single stack to customers. It will provide you the choice of storage platform (well needs to be Tintri of course), hypervisor, compute and network infrastructure. It can also include things like OpenStack or the vRealize Suite. Personally I think this is a smart move, but this is something I would have preferred to have seen launched 12-18 months ago. Nevertheless, it is a good move.

 For Virtual SAN they are not using blades any longer but instead switched to rack mounted servers. Considering the low number of VMs that are typically running in these offshore environments a fairly “basic” 1U server can be used. With 4 hosts you will now only take up 4U , instead of the 8 or 10U a typical blade system requires. Before I forget, the hosts itself are Lenovo
For Virtual SAN they are not using blades any longer but instead switched to rack mounted servers. Considering the low number of VMs that are typically running in these offshore environments a fairly “basic” 1U server can be used. With 4 hosts you will now only take up 4U , instead of the 8 or 10U a typical blade system requires. Before I forget, the hosts itself are Lenovo