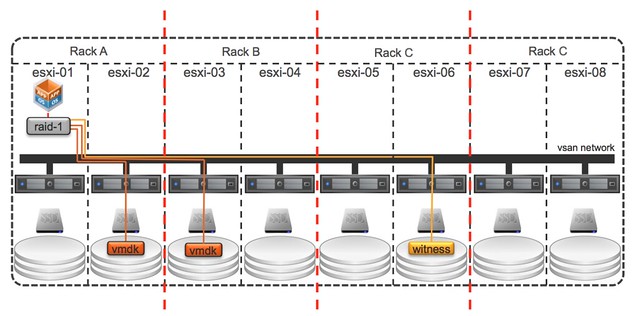
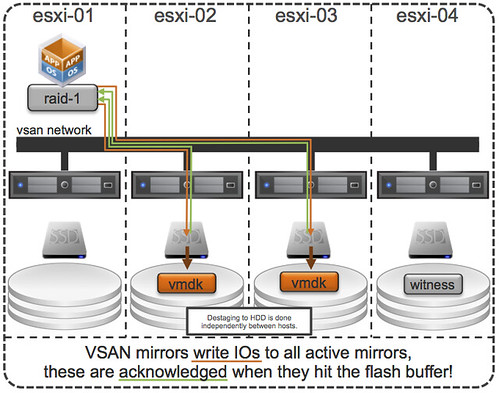
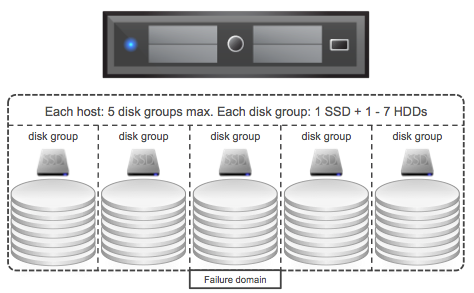
I was talking to a customer this week who was looking to deploy various 4 node VSAN configurations. They needed a solution which would provide them performance and wanted to minimize the moving components due to the location and environmental aspects of the deployment, all-flash VSAN is definitely a great choice for this scenario. I looked at various server vendors and based on their requirements (and budget) provided them a nice configuration (in my opinion) which comes in for slightly less than $ 45K.
What I found interesting is the price of the SSDs, especially the “capacity tier” as the price is very close to SAS 10K RPM. I selected the Intel S3500 as the capacity tier as it was one of the cheapest listed that is part of the VMware VSAN HCL, will be good to track GB/$ for new entries on the HCL that will be coming soon, so far S3500 seems to be the sweet spot. Also seems that from a price point perspective the 800GB devices are most cost effective at the moment. The 3500 seems to perform well as demonstrated in this paper by VMware on VSAN scaling / performance.
This is what the bill of materials looked like, and I can’t wait to see it deployed:
- Supermicro SuperServer 2028TP-HC0TR – 2U TwinPro2
- Each node comes with:
- 2 x Eight-Core Intel Xeon Processor E5-2630 v3 2.40GHz 20MB Cache (85W)
- 256 GB in 8 DIMMs at 2133 MHz (32GB DIMMs)
- 2 x 10GbE NIC port
- 1 x 4
- Dual 10-Gigabit Ethernet
- LSI 3008 12G SAS
That is a total of 16TB of flash based storage capacity, 1TB of memory and 64 cores in mere 2U. The above price is based on a simple online configurator and does not include any licenses, a very compelling solution if you ask me.

 EMC
EMC 
 That is a nice long list indeed. Let my discuss some of these features a bit more in-depth. First of all “all-flash” configurations as that is a request that I have had many many times. In this new version of VSAN you can point out which devices should be used for caching and which will serve as a capacity tier. This means that you can use your enterprise grade flash device as a write cache (still a requirement) and then use your regular MLC devices as the capacity tier. Note that of course the devices will need to be on the HCL and that they will need to be capable of supporting 0.2 TBW per day (TB written) over a period of 5 years. For a drive that needs to be able to sustain 0.2 TBW per day, this means that over 5 years it needs to be capable of 365TB of writes. So far tests have shown that you should be able to hit ~90K IOPS per host, that is some serious horsepower in a big cluster indeed.
That is a nice long list indeed. Let my discuss some of these features a bit more in-depth. First of all “all-flash” configurations as that is a request that I have had many many times. In this new version of VSAN you can point out which devices should be used for caching and which will serve as a capacity tier. This means that you can use your enterprise grade flash device as a write cache (still a requirement) and then use your regular MLC devices as the capacity tier. Note that of course the devices will need to be on the HCL and that they will need to be capable of supporting 0.2 TBW per day (TB written) over a period of 5 years. For a drive that needs to be able to sustain 0.2 TBW per day, this means that over 5 years it needs to be capable of 365TB of writes. So far tests have shown that you should be able to hit ~90K IOPS per host, that is some serious horsepower in a big cluster indeed.