I typically don’t do these short posts which simply point to a white paper, but I really liked this paper on the topic of VMware Horizon View and All-Flash VSAN. In the paper it is demonstrated how to build an all-flash VSAN cluster using Dell servers, SanDisk flash and Brocade switches. Definitely recommended read if you are looking to deploy Horizon View anytime soon.
VMware Horizon View and All Flash Virtual SAN Reference Architecture
This Reference Architecture demonstrates how enterprises can build a cost-effective VDI infrastructure using VMware All Flash Virtual SAN combined with the fast storage IO performance offered by SSDs. The combination of Virtual SAN and all flash storage can significantly improve ROI without compromising on the high availability and scalability that customers demand.
 This week I had the pleasure of talking to fellow dutchy
This week I had the pleasure of talking to fellow dutchy  The conversation of course didn’t end there, lets get in to some more details. We discussed the use case first. PeaSoup is a hosting / cloud provider. Today they have two clusters running based on Virtual SAN. They have a management cluster which hosts all components needed for a vCloud Director environment and then they have a resource cluster. The great thing for PeaSoup was that they could start out with a relatively low investment in hardware and scale fast when new customers on-board or when existing customers require new hardware.
The conversation of course didn’t end there, lets get in to some more details. We discussed the use case first. PeaSoup is a hosting / cloud provider. Today they have two clusters running based on Virtual SAN. They have a management cluster which hosts all components needed for a vCloud Director environment and then they have a resource cluster. The great thing for PeaSoup was that they could start out with a relatively low investment in hardware and scale fast when new customers on-board or when existing customers require new hardware. Harold pointed out that the only down side of this particular Fujitsu configuration was the fact that it only came with a disk controller that is limited to “RAID O” only, no passthrough. I asked him if they experienced any issues around that and he mentioned that they had 1 disk failure so far and that is resulted in having to reboot the server in order to recreate a RAID-0 set for that new disk. Not too big of a deal for PeaSoup, but of course if possible he would prefer to prevent this reboot from being needed. The disk controller by the way is based on the LSI 2208 chipset and it is one of things PeaSoup was very thorough about, making sure it was supported and that it had a high queue depth. The “HCL” came up multiple times during the conversation and Harold felt that although doing a lot of research up front and creating a scalable and repeatable architecture takes time, it also results in a very reliable environment with predictable performance. For a cloud provider reliability and user experience is literally your bread and butter, they couldn’t afford to “guess”. That was also one of the reasons they selected a VSAN Ready Node configuration as a foundation and tweaked where their environment and anticipated workload would require it.
Harold pointed out that the only down side of this particular Fujitsu configuration was the fact that it only came with a disk controller that is limited to “RAID O” only, no passthrough. I asked him if they experienced any issues around that and he mentioned that they had 1 disk failure so far and that is resulted in having to reboot the server in order to recreate a RAID-0 set for that new disk. Not too big of a deal for PeaSoup, but of course if possible he would prefer to prevent this reboot from being needed. The disk controller by the way is based on the LSI 2208 chipset and it is one of things PeaSoup was very thorough about, making sure it was supported and that it had a high queue depth. The “HCL” came up multiple times during the conversation and Harold felt that although doing a lot of research up front and creating a scalable and repeatable architecture takes time, it also results in a very reliable environment with predictable performance. For a cloud provider reliability and user experience is literally your bread and butter, they couldn’t afford to “guess”. That was also one of the reasons they selected a VSAN Ready Node configuration as a foundation and tweaked where their environment and anticipated workload would require it.
 Last week I had the chance to catch up with one of our Virtual SAN customers. I connected to
Last week I had the chance to catch up with one of our Virtual SAN customers. I connected to 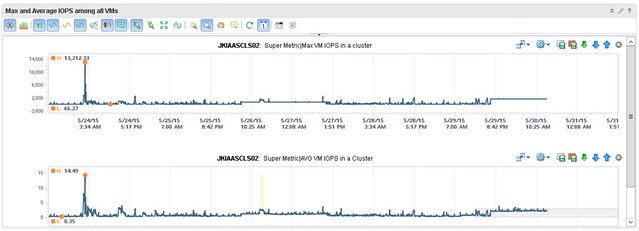
 Last week on twitter there was a discussion about hyper-converged solutions and how these were not what someone who works in an enterprise environment would buy for their tier 1 workloads. I asked the question: well what about buying Pure Storage, Tintri, Nimble or Solid Fire systems? All non-hyper converged solutions, but relatively new. Answer was straight forward: not buying those either, big risk. Then the classic comment came:
Last week on twitter there was a discussion about hyper-converged solutions and how these were not what someone who works in an enterprise environment would buy for their tier 1 workloads. I asked the question: well what about buying Pure Storage, Tintri, Nimble or Solid Fire systems? All non-hyper converged solutions, but relatively new. Answer was straight forward: not buying those either, big risk. Then the classic comment came: