I noticed a tweet today which made a statement around the use of eager zero thick disks in a VSAN setup for running applications like SQL Server. The reason this user felt this was needed was to avoid the hit on “first write to block on VMDK”, it is not the first time I have heard this and I have even seen some FUD around this so I figured I would write something up. On a traditional storage system, or at least in some cases, this first write to a new block takes a performance penalty. The main reason for this is that when the VMDK is thin, or lazy zero thick, the hypervisor will need to allocate that new block that is being written to and zero it out.
First of all, this was indeed true with a lot of the older storage system architectures (non-VAAI). However, this is something that even in 2009 was dispelled as forming a huge problem. And with the arrival of all-flash arrays this problem disappeared completely. But indeed VSAN isn’t an all-flash solution (yet), but for VSAN however there is something different to take in to consideration. I want to point out, that by default when you deploy a VM on VSAN you typically do not touch the disk format even and it will get deployed as “thin” with potentially a space reservation setting which comes from the storage policy! But what if you use an old template which has a zeroed out disk and you deploy that and compare it to a regular VSAN VM, will it make a difference? For VSAN eager zero thick vs thin will (typically) make no difference to your workload at all. You may wonder why, well it is fairly simple… just look at this diagram:
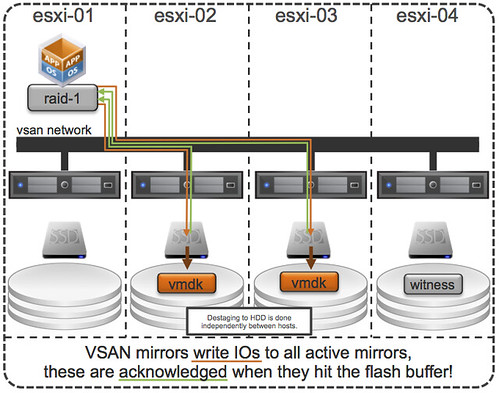
If you look at the diagram then you will see that the acknowledgement will happen to the application as soon as the write to flash has happened. So in the case of thick vs thin you can imagine that it would make no difference as the allocation (and zero out) of that new block would happen minutes after the application (or longer) has received the acknowledgement. A person paying attention would now come back and say: hey you said “typically”, what does that mean? Well that means that the above is based in the understanding that your working set will fit in cache, of course there are ways to manipulate performance tests to proof that the above is not always the case, but having seen customer data I can tell you that this is not a typical scenario… or extremely unlikely.
So if you deploy Virtual SAN… and have “old” templates floating around and they have “EZT” disks, I would recommend overhauling them as it doesn’t add much, well besides a longer waiting time during deployment.
Even in conventional storage, I never understood why on earth would you actually go and write zeros. If it is first write, just write whatever. If it is first read, just answer zeros. The only reason would be, AFAIK, security of old data. And if you dare to believe in the OS by doing lazy zeroing, why would you ddistrust at the last second ?
Oh, I feel ignored 🙁
…feeling that forced me to think a little more.
And I conclude, that the only reason to use eager is that some entity reads those blocks using some alternative path, i.e., not funneled through the (local?) ESXi. FT fits the bill, as does any system that does direct storage access for replication or backup.
My apologies for not responding sooner. You are right that it should be possible to return zeroes, however the blocksize of VMFS is 1MB and the writes / reads could be smaller and VMFS doesn’t track which section of a 1MB block has been written to. From a security standpoint it was as such decided to take the safe route and zero out the full block.
Great, that makes total sense, I had not taken that (block size mismatch) into account.
Nor have I seen it mentioned anywhere. Thanks for sharing!
Duncan,
I agree with the conclusion, VMDK format should not matter with VSAN as all writes are acknowledged upon hitting the SSD cache and not the actual VMDK file.
I do find faults in the test results of the performance impact of thin virtual disks as the testing was executed with Iometer. As Iometer creates a file of a predefined size which to execute the IO operations, the underlying thin VMDK is allocating and formatting the blocks to store the Iometer file. While the VMDK is thin, the IO testing is occurring in a range that has been allocated prior to the IO load initiating.
A better test would have been to use FIO, which allocates space as the IO load is being generated. With FIO one could easily identify the overhead of VMFS block allocation and VMDK formatting with a thin VMDK on VMFS with the array management of blocks with a NFS datastore. I can put you in contact with customers who have ran such tests – the results are wild.
This raises a question, what is the underlying file system and storage protocol used with VSAN? I get a sense its more NFS-like than VMFS-like.
Thanks for the post.
— cheers,
v
Let me point you to an article by this all-flash storage company then which may convince you: http://www.purestorage.com/blog/vm-performance-on-flash-part-2-thin-vs-thick-provisioning-does-it-matter/
Also, VSAN (in the 5.5) release uses VMFS-L as its file system underneath. This is abstracted away from the user however so you wouldn’t normally see this.
The only case where I can see this actually mattering is if your steady state write IOPS are high enough to fill the cache (In which case, you would have had performance problems anyways, and need to add spindles, or improve the speed/iops of the capacity disks in the disk group). In theory if you had a burst of stead state writes to new blocks this would double the time to cache exhaustion. Normally this would be on a streaming write workload, and this is something that if your using even NL-SAS for on the back end, the back end disks should coalesce the writes as the Tagged Command Queuing de-stages out similar LBA writes (or your using SATA where the NCQ isn’t quite as good).
So now we are in search of a mythical, random write burst workload with LBA’s so skewed all over the place, that TCQ can’t pick it up, and the theoretical 2:1 write amplification in the short term is an issue.
Considering VSAN is aimed at 95% of the workloads, and not going for the 7 x 9’s of IO consistency that drives people to traditional Tier 1 big iron arrays, or all flash I’d argue the “current” implementation with a standard FIFO write buffer is “good enough” that I REALLY wouldn’t be worried about this for any of our VSAN customers or deployments.
Long term either an all flash configuration, or moving to some sort of tiering, or elevator sorting write cache (With coalescing before cache de-stage) would prevent this from being something you might be able to recreate in a lab.
As you point out writes are the easy thing to cheat. Data skew and reads are the harder part that everyone ignores for some reason (And yet VSAN has better ways to cheat reads too, with cache reservations and striping, IOP restrictions and proper sizing tools).
(It looks like this got double posted on the newer post if you’d like to delete it from there).
Vaughn,
I did see HDS”s testing on this (and have done my own with their gear in labs).
http://www.hds.com/assets/pdf/advantages-of-using-vmware-vaai-on-hus-100-family.pdf
It is true on traditional non-flash assisted arrays that in the narrow context of doing new LBA writes to a thin VMDK, for beyond the controller cache’s write size you will experience a slowdown.
Considering write cache costs 1/50th the cost for VSAN vs. traditional arrays, this means its going to be a LOT longer before you’ll hit this wall in a proper sized enviroment.
One of the more write heavy environments I work in (VDI with linked clones) this hasn’t been an issue for (even when using 7200RPM drive for back end). It just doesn’t take much time for the writes to evict from cache.
Correct, that is one scenario where you will probably see a decrease in performance, although as you point out that is highly theoretical and not likely to happen in any VSAN environment today or tomorrow for that matter.
PS: deleted the other one, thanks for the long reply by the way…