A while ago I wrote this article on the topic of “one versus multiple disk groups“. The summary was that you can start with a single disk group, but that from a failure domain perspective having multiple disk groups is definitely preferred. Also from a performance stance there could be a benefit.
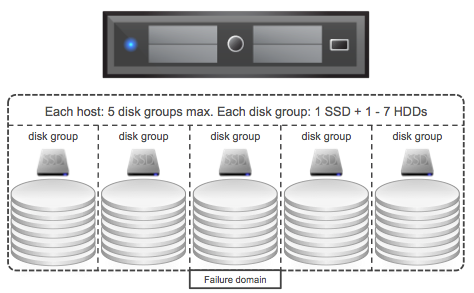
So the question now is, what about all-flash VSAN? First of all, same rules apply: 5 disk groups max, each disk group 1 SDD for caching and 7 devices for capacity. There is something extra to consider though. It isn’t something I was aware off until I read the excellent Design and Sizing Guide by Cormac. It states the following:
In version 6.0 of Virtual SAN, if the flash device used for the caching layer in all-flash configurations is less than 600GB, then 100% of the flash device is used for cache. However, if the flash cache device is larger than 600GB, the only 600GB of the device is used for caching. This is a per-disk group basis.
Now for the majority of environments this won’t really be an issue as they typically don’t hit the above limit, but it is good to know when doing your design/sizing exercise. The recommendation of 10% cache to capacity ratio still stands, and this is used capacity before FTT. If you have a requirement for a total of 100TB, then with FTT=1 that is roughly 50TB of usable capacity. When it comes to flash this means you will need a total of max 5TB flash. That is 5TB of flash in total, with 10 hosts that would be 500GB per host and that is below the limit. But with 5 hosts that would be 1TB per host which is above the 600GB mark and would result in 400GB per host being unused?
Well not entirely, although the write buffer has a max size of 600GB, note that the remainder of the capacity is used by the SSD for endurance, so it will cycle through those cells… and that is also mainly what you are sizing for when it comes to the write buffer. That 10% is mainly around endurance. So you have a couple of options, you can have multiple disk groups to use the full write buffer capability if you feel you need that, or you can trust on VSAN and the flash “internals” to do what they need to do… I have customers doing both, and I have never heard a customer “complain” about the all-flash write-buffer limit… 600GB is a lot to fill up.
Max or min 5TB flash? 10% is a practically lower limit right?
There is no min or max really, it is recommendation. You could go with 50GB per host if you want to. The performance experience is just going to be different 🙂
But in either way I can’t use more then 600GB SSD per host(I hope you are speaking of SSD’s when saying flash) ?
So what happens to the rest of 400GB in your case of 5 hosts with 1TB of SSD’s, that goes waste ?
Is that 600GB limit per host set by VMware for SSD’s ?
Why would VMware set a limit on SSD’s per host if someone can afford more SSD’s it should be allowed for faster speed, shouldn’t it ?
Hold on, not more than 600GB SSD per disk group. You can have 5 disk groups. With a 10% flash to capacity ratio you can have 6TB SSD per disk group for capacity and 600GB as the write cache. That is 30TB of SSD per host max.
Lets say If I create a DG with 900g SSD, only 600g is used and 300 is unused?
If this is an “all-flash” disk group then you are correct. but this means that the capacity tier is also coming from flash!
How does this affect me if I want a configuration with a disk group geometry of 4x 6TB capacity SSD’s, two disk groups per node?
So if all drives are flash, no need for cache? I don’t see any need for de-staging since no capacity tier exists. Back to 600g limit, is that not configurable parameter? I am sure there is a good reason why the cache limit is set to 600g.
You need a “write cache”, which is of a different type of flash typically then the capacity layer which serves mainly reads. Endurance of the flash device is key here
you mean different like SLC, eMLC type?
Yes, cache tier (write) is expected to be able to endure 2TB of writes per day. The capacity tier only requires 0.2TB
Right… I missed to take in account FTT values last time i estimated the flash size.
Is there any performance comparison between one vs multiple disk groups. Does this scale linear? Is there memory overhead involved doing so?
One diskgroup vs. multiple disk groups. I just thought about that you said: “More disk groups and more flash is always better if you ask me! more cache + more failure domains (diskgroup)” I would be interessted to use a scientific approach to prove or unprove that more diskgroups with ssd may fail less then one PCe with the same amount of disks. (I know you are not able to build one disk group with 5*7 disks) Just for calculation.
Just thinking out loud here.
In All Flash VSAN, the SSD is ONLY for write cache. If your deploying say a 4 node cluster with a single disk group each and 4 x 600GB High Endurance drives for the cache, that means you have 1.2TB of Write cache. Lets think about that for a minute. That is 1.2TB of burst writes (and while thats happening its also de-staging out to the back end flash disks). Even assuming your write cache can absorb data at 2x the rate it can read it back out to the capacity tier flash and it can de-stage it (unlikely), that means your going to be “exhausting” your write cache after 2.4TB of sustained burst write (Well 1.2TB after write mirroring). THIS IS A LOT OF DATA. My old FC spinning drive based array in the corner only had 16GB of Write Cache.
If I wanted this much write cache 3 years ago I’d be buying a heavy six/seven figure multi-engine VMAX or VSP configuration.
Realistically if this limit is a problem it means one of a few things.
1. Your back end flash is really slow!
2. Your steady state writes are so insane, you likely need to scale out to more disk groups, and hosts for port/throughput reasons.
In an all flash array system the write cache is really more about being a place to coalesce writes, and protect flash from burning out, than a performance tier for busty workloads.
Just looking at the flash we having laying around the office (Micron M500 for capacity, Intel S3700 for write cache) these drives are fairly closely matched on performance. The 4x difference in price is about endurance plane and simple. In fact, I’d argue for maximum performance I really should be looking at a DIMM or PCI-Express, or NVMe drives for my write tier, as technically the write IOPS bottleneck would be the S3700 by a long shot if I had a fully loaded disk group.
If I was just wanting performance over capacity I’d want to scale out with more, smaller disk groups at the least.
Agreed, but this is not the reason for the limit to be honest… but you make a very good point and I agree that scale-out makes much more sense then scale-up.
Regarding the comment about having TB of “cache”, compared to GB on a disk array. Remember that the cache on the disk array is DRAM, with nanosecond latency, compared to SSD, which is high microsecond to low millisecond latency. It’s still very fast, but you need to be aware of the architecture differences when comparing traditional disk array cache with VSAN cache.
Hello Duncan, planning to get some high volume DB servers on VSAN. These servers are around 32TB database size . We have moved all the web , apps , mid tier, batch servers to VSAN and we are happy with the performance. Not sure to get the DB servers . Please Let me know your views.
That is a good question Balaji and an interesting one. It will depend on the IO profile and the configuration of your hosts. I will drop you an email to discuss, a bit easier 🙂
Hi Duncan – two questions:
1. With SSDs getting bigger and cheaper, there is or will be a need to support more than 600GB cache devices. Is this in the works and is there anything you can share about it?
2. Can you confirm that in a typical environment, where people use two copies of their data, you should size your cache for 5% of raw capacity tier capacity, or even a little less since nobody fills up their systems completely? Example: 7 x 960GB SSD for capacity tier is 900GB formatted, yielding 6.1TB of raw capacity. FTT=1 yields 3TB of usable capacity. Common sense IT practices say you shouldn’t fill up the system more than about 80% before buying new space. Now you’re down to maybe 2.5TB of usable capacity. 10% of THAT is only 250GB of cache. Even a 240GB drive would be big enough to reasonably meet the 10% guideline.
Thanks!
1. Yes, we filed a request to have this increased. It is actively being looked at, I cannot commit to a date however
2. You are correct. The “official rule” is 10% of expected used capacity before FTT. Now, I usually don’t take slack space in to account, but I do take FTT in to account.