Starting with vSAN 8 a brand new architecture was introduced called “Express Storage Architecture”. Over the last year or so a lot of information has been shared about ESA and the benefits of ESA. One of the things which ESA introduces is much-improved snapshot scalability.
With vSAN OSA, and with VMFS, when you create a snapshot you typically immediately see a performance degradation. This is because both VMFS and vSAN OSA still operate using the redo-log based snapshot mechanism. This means that with vSAN OSA when you create a snapshot a new object is created and writes are re-directed. It also means that reads will be coming from various files, if you have one or more snapshots. This mechanism is, unfortunately, not very effective. Let me borrow a diagram that is part of a post John Nicholson wrote to demonstrate that old logic.
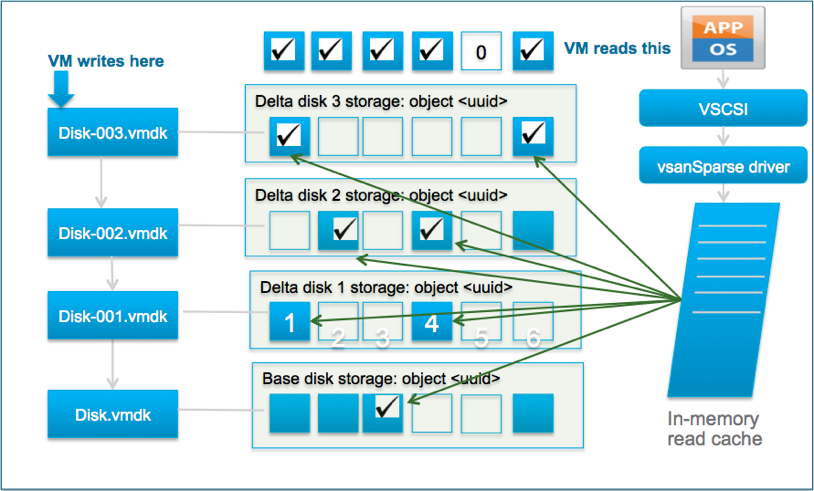
With vSAN 8 ESA the mechanism has changed and no longer does vSAN, or vSphere for that matter, create an additional object. vSAN ESA handles this on a meta-data level. In other words, instead of redirecting writes and traversing files for reads, vSAN now leverages a highly efficient B-Tree structure and pointers to keep track of which block is associated with which snapshot.
Not only is this more efficient from a capacity perspective, but more importantly it is very efficient from a performance standpoint. I ran half a dozen tests in my lab, and what I saw was a below 2% performance impact between a VM without a snapshot and a VM with one or multiple snapshots. I could NOT see a significant difference between the first or the fifth snapshot. I do want to point out that my lab is not officially certified to run vSAN ESA, nevertheless, I was very impressed with the results.
During the last run, I actually recorded the whole exercise. In this demo, I show the creation of one snapshot, while the VM is running a benchmark (HCIBench). Now, during the testing, I created not one but various snapshots and of course, I deleted all of them as well. You have all probably experienced extensive stun times during the deletion of a snapshot at times, and this is where vSAN ESA shines. The stun times have been reduced by 100 times, and that is something I am sure each of you will appreciate. Why have they been reduced drastically? Well, simply because we no longer have to copy data from one vSAN object to another. This makes a huge difference, not just for stun times, but also for performance in general (latency, IOPS, throughput). If you are interested, have a look at the demo!