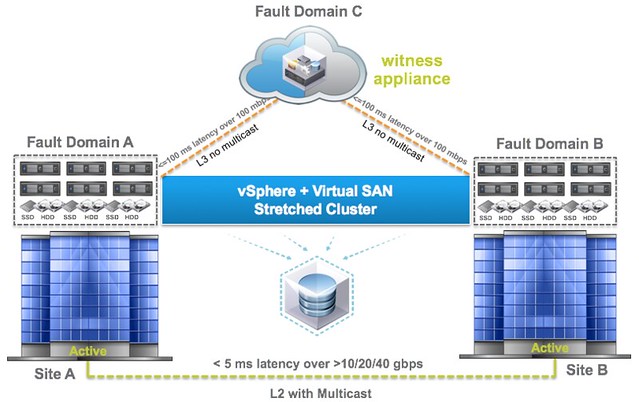
This question is going to come sooner or later, how do I configure HA/DRS when I am running a Virtual SAN Stretched cluster configuration. I described some of the basics of Virtual SAN stretched clustering in a what’s new for 6.1 post already, if you haven’t read it then I urge you to do so first. There are a couple of key things to know, first of all the latency between data sites that can be tolerated is 5ms and to the witness location ~100ms.
If you look at the picture you below you can imagine that when a VM sits in Fault Domain A and is reading from Fault Domain B that it could incur a latency of 5ms for each read IO. From a performance perspective we would like to avoid this 5ms latency, so for stretched clusters we introduce the concept of read locality. We don’t have this in a non-stretched environment, as there the latency is microseconds and not miliseconds. Now this “read locality” is something we need to take in to consideration when we configure HA and DRS.
 [Read more…] about HA/DRS configuration with Virtual SAN Stretched Cluster environment
[Read more…] about HA/DRS configuration with Virtual SAN Stretched Cluster environment
