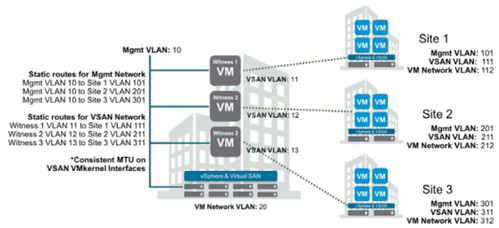
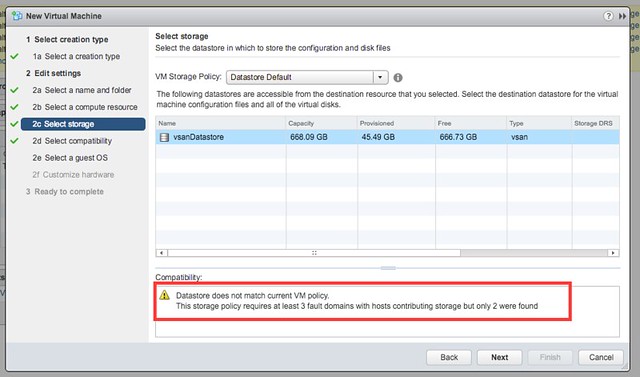
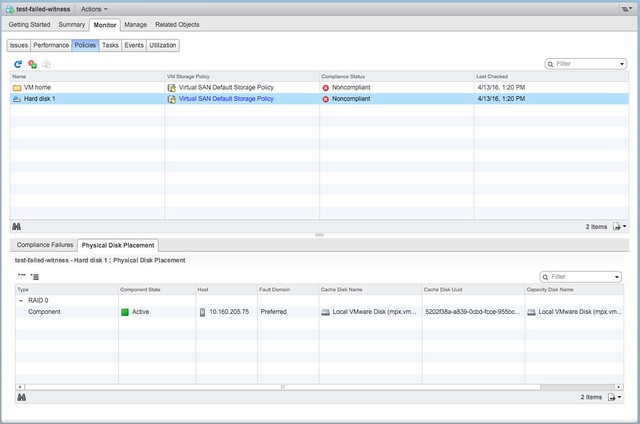
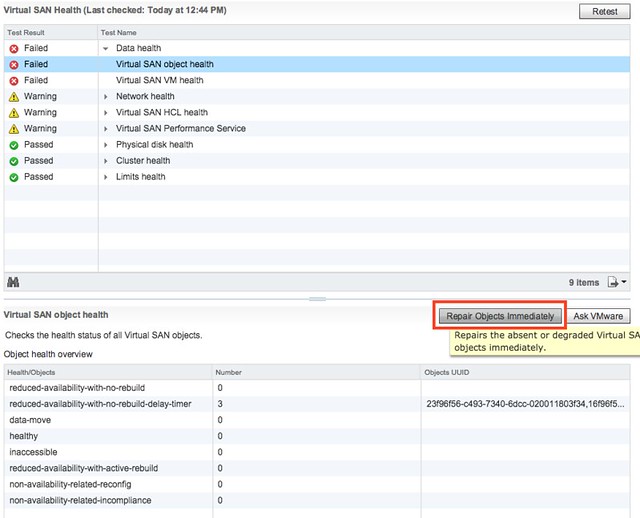
I had one more demo to finish and share and that is the vSAN 6.6 stretched cluster demo. I already did a stretched clustering demo when we initially released it, but with the enhanced functionality around local protection I figured I would re-record it. In this demo (~12 minutes) I will show you how to configure vSAN 6.6 with dedupe / compression enabled in a Stretched Cluster configuration. I will also create 3 VM Storage Policies, assign those to VMs and show you that vSAN has place the data across locations. I hope you find it useful.