** UPDATE 20-March 2016 **
When using vSphere 6.0 or higher, please be advised that Disk.AutoremoveOnPDL needs to be set to 1 (default value) in order for “PDL Scenarios” to be handles correctly in vMSC based infrastructures. Please do not change the default value, or when upgrading to vSphere 6.x please set this value to 1 when changed in previous version.
** UPDATE 20-March 2016 **
Last week I tweeted the recommendation to disable the advanced setting Disk.AutoremoveOnPDL in a vSphere 5.5 vMSC environment:
https://twitter.com/DuncanYB/status/394740133079298048
Based on this tweet I received a whole bunch of questions. Before I explain why I want to point out that I have contacted the folks in charge of the vMSC program and have requested them to publish a KB article asap on this subject.
With vSphere 5.5 a new setting was introduced called “Disk.AutoremoveOnPDL”. When you install 5.5 this setting is set to 1 which means it is enabled. What it does is the following:
The host automatically removes the PDL device and all paths to the device if no open connections to the device exist, or after the last connection closes. If the device returns from the PDL condition, the host can discover it, but treats it as a new device. Data consistency for virtual machines on the recovered device is not guaranteed.
In a vMSC environment you can understand that removing devices which are in a PDL state is not desired. As when the issue that caused the PDL has been solved (from a networking or array perspective) customers would expect the LUNs to automatically appear again. However, as they have been removed a “rescan” is needed to show these devices again instantly, or you will need to wait for the vSphere periodic path evaluation to occur. As you can imagine, in a vSphere Metro Storage Cluster environment (stretched storage) you expect devices to always be there instantly on recovery… even when they are in a PDL or APD state they should be available instantly when the situation has been resolved.
For now, I recommend to set Disk.AutoremoveOnPDL to 0 instead of the default of 1:
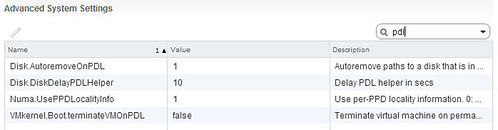
Hopefully soon this KB on the topic of Disk.AutoremoveOnPDL will be updated to reflect this.


