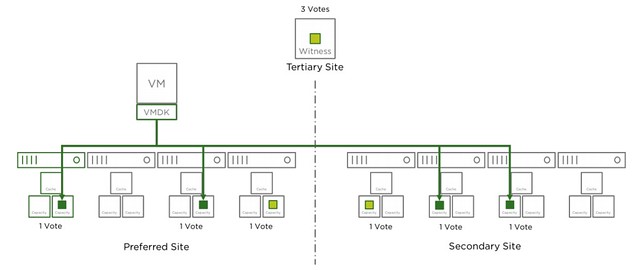
I was at a customer last week and had an interesting question about the vSAN voting mechanism. This customer had a stretched cluster and used RAID-5 within each location to protect the data on top of replicating across locations. During certain failure scenarios unexpectedly the data remained available, of course, it is great that you have higher availability than expected, but why did this happen? What this customer tested was powering off the Witness (which is deemed as a site failure) and next powered of 2 hosts in 1 location, which exceeds the “failures to tolerate” in a single location. You would expect, based on all documentation so far, that the data would be unavailable. Well for some VMs this was the case, but for others, that was not the case. Why is this? Well, it is all about the vote count in this case. Look at the below diagram and the number of votes for each component first.

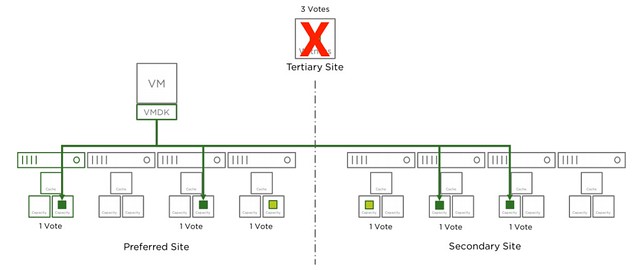
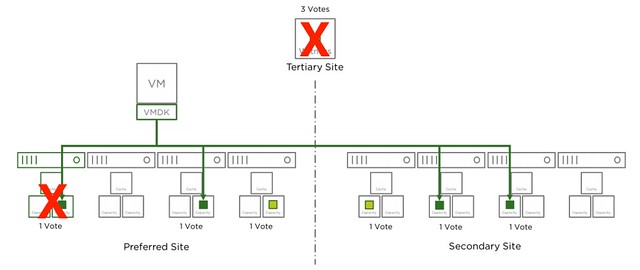
In the above scenario if the Witness (W) fails we have 4 votes less. Out of a total of 13 that is not a problem. If two additional hosts fail, this is most likely still not a problem, even though you are exceeding the provided “failures to tolerate”. However, if by any chance Host1 is one of those failed hosts then you would lose quorum. Host1 has a component with 2 votes. So if host1 has failed and the witness has failed and host2 for instance, you have now lost 7 out of 13 votes. This means quorum is lost. Please note that that single component with 2 votes is random. For a different VM/Object it could be that the component which is placed on host6 or host7 has 2 votes.
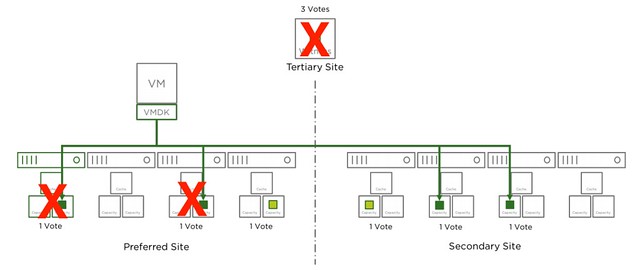
Another thing to point out, if host5-8 all would fail the data is still available. However, if then host3 and host4 would fail the object would become unavailable. Even though you still would have quorum across locations, you have now also exceeded the specified “failures to tolerate” within the location. This is also something that will be taken in to account.
I hope that helps.