This session I had high on my list to go and watch live. Unfortunately, I was double booked during the show, hence I had to watch “HCI2476BU – Tech Preview RDMA and next-gen storage tech for vSAN” online as well. This session was by my colleagues Biswa and Srinath (PM/Engineering) and discusses how we can potentially use RDMA and next-gen storage technology for vSAN.
I am not going to cover the intro, as all readers by now are well aware of what vSAN is and does. What I think was interesting was the quick overview of the different types of ready nodes we have available. Recently included is the Cisco E-Series which is intended for Edge Computing scenarios. Another interesting comment was around some of the trends in the market around CPU, it seems that “beefy” single-socket servers are gaining traction. Not entirely surprising considering it lowers the licensing considerably and you can go up to 64 cores per CPU with AMD EPYC. Next up is the storage aspect of things, what can we expect in the upcoming years?
Biswa mentions that there’s a clear move towards the adoption of NVMe, moving away from SAS/SATA. It is expected that the NVMe devices will be able to deliver 500k+ of IOPS in the next 2 years. Just think about that. 500k IOPS from a single device. Biswa also briefly touched on DDR4 based Persistent Memory, where we can expect million(s) of IOPS with nanoseconds of latency. Next various types of devices are discussed and the performance and endurance capabilities. Even if you consider what is available today, it is a huge contrast compared to 1-2 years ago. Of course, all of this will come at a cost. From a networking perspective 10G/25G/40G is mainstream now or becoming, and RDM enabled (RoCE) NIC is becoming standardized as well. 100G will become the new standard, but this will take 3-5 years at a minimum.
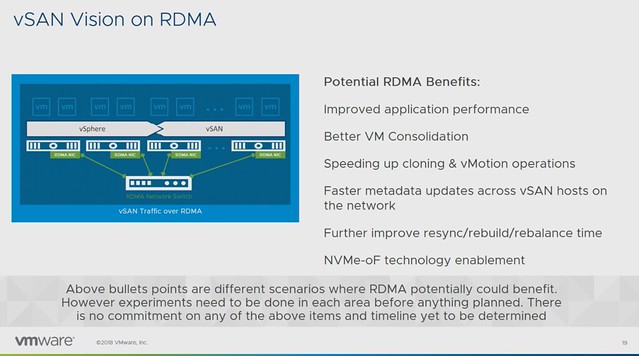
Before the RDMA section started a quick intro to RDMA was provided: “Remote direct memory access from one computer into that of another without involving either one’s operating system allows for high throughput and low latency, which is especially useful in massive parallel computer clusters”. The expected potential / benefits for vSAN is:
- Improved application performance
- Better VM Consolidation
- Speeds up cloning & vMotion
- Faster metadata updates
- Faster resync/rebuild times
- NVMe-oF technology enablement
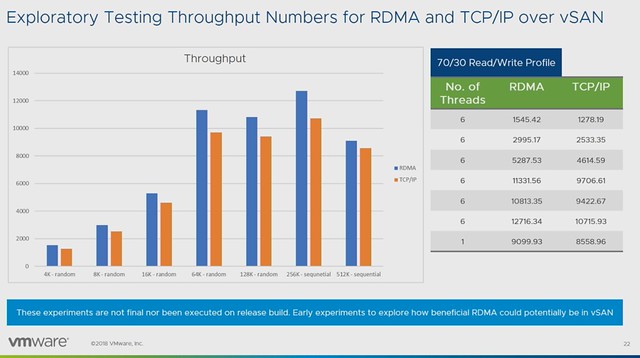
Early performance tests show a clear performance benefit for using RDMA. Throughput and IOPS are clearly higher, while latency is consistency lower when comparing RDMA to TCP/IP. Note that vSAN has not been optimized in these particular cases yet and this is just one example of a particular workload on a very specific configuration. (Tests were conducted with Mellanox.)
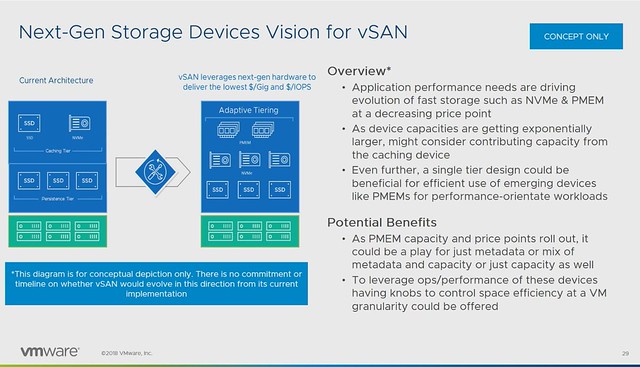
But what about that “next-gen storage”? How can we use this to increase IOPS/throughput while lowering not only latency but also HCI “overhead” like CPU and Memory consumption? Also, what does it mean for the vSAN architecture, what do we need to do to enable this? Faster networks, faster devices may mean that changes are required to various modules/processes. (Like DOM, LSOM, CLOM etc.)
Persistent Memory is definitly one of those next-gen storage devices which will require us to rethink the architecture. Simply because of the ultra low latency, the lower the latency the higher the overhead of the storage stack appears to be. Especially when we are reaching access times which are close to memory speeds. Can we use these devices in an “adaptive tiering” architecture where we use PMEM, NVMe and SSDs? Where for instance PMEM is used for metadata, or even metadata and capacity for hot blocks?
Last but not least a concept demo was shown around NVMe-oF for vSAN. Meaning that NVMe over Fabric allows you to present (additional) capacity to ESXi/vSAN hosts. These devices would be “JBOF”, aka “just a bunch of flash” connected over RDMA / NVMe-oF. In other words, these hosts had no direct locally attached storage, but instead these NVMe devices are presented as “local devices” across the fabric. Which, potentially, allows you to present a lot of storage to hosts which have no local storage capabilities even(Blades anyone?). Also, I wonder if this would allow us in the future to have similar benefits of fabric connected devices as for instance VMware Cloud on AWS has. Meaning that devices can be connected to other hosts after a failure, so that a resync/rebuild can be avoided? Food for thought definitely.
Make sure to watch “HCI2476BU – Tech Preview RDMA and next-gen storage tech for vSAN” online if you want to know more, as it doesn’t appear to be scheduled for VMworld Europe!
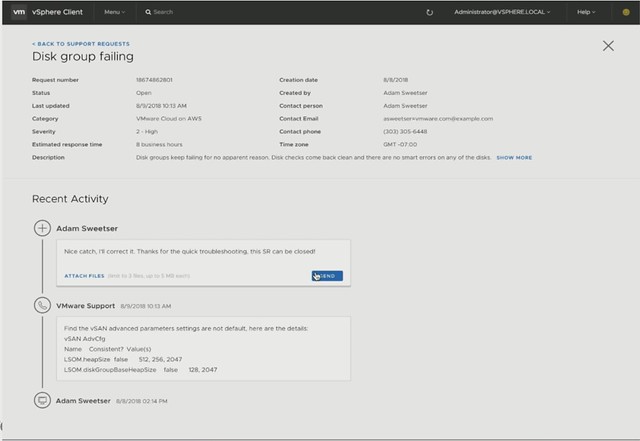
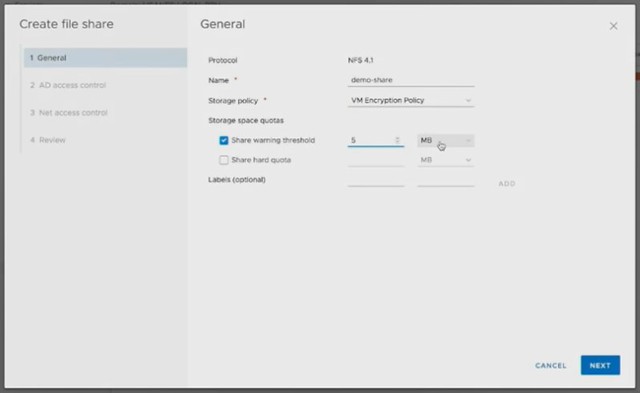
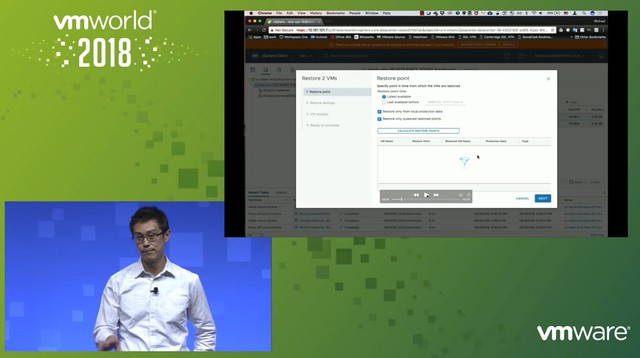 Michael started out with an explanation about what an SSDC brings to customers, and how a digital foundation is crucial for any organization that wants to be competitive in the market. vSAN, of course, is a big part of the digital foundation, and for almost every customer data protection and data recovery is crucial. Michael went over the various vSAN use cases and also the availability and recoverability mechanisms before introducing Native vSAN Data Protection.
Michael started out with an explanation about what an SSDC brings to customers, and how a digital foundation is crucial for any organization that wants to be competitive in the market. vSAN, of course, is a big part of the digital foundation, and for almost every customer data protection and data recovery is crucial. Michael went over the various vSAN use cases and also the availability and recoverability mechanisms before introducing Native vSAN Data Protection.