Various people have asked me, and I wrote about this before in several articles but as part of a longer article which makes it difficult to find. When specifying the restart priority or restart dependency you can specify when the next batch of VMs should be powered on. Is that when the VMs are powered on when they are scheduled for being powered on, when VMware Tools reports them as running or when the application heartbeat reports itself?
In most cases, customers appear to go for either “powered on” or “VMware Tools” heartbeat. But what happens when one of the VMs in the batch is not successfully restarted? Well HA waits… For how long? Well that depends:
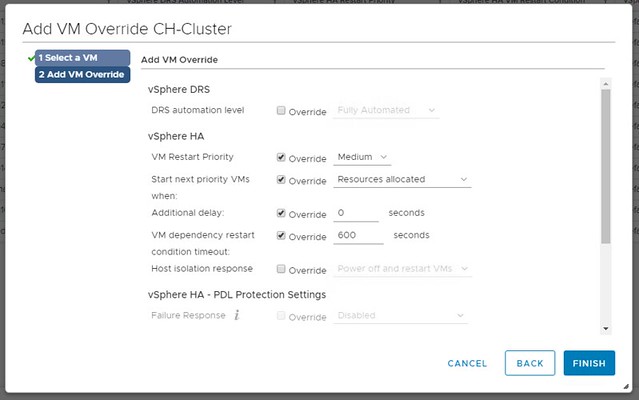
In the UI you can specify how long HA needs to wait by using the option called “VM Dependency Restart Condition Timeout”. This is the time-out in seconds used when one (or multiple VMs) can’t be restarted. So we initiate the restart of the group, and we will start the next batch when the first is successfully restart or when the time-out has been exceeded. By default, the time-out is 600 seconds, and you can override this in the UI.
What is confusing about this setting is the name, it states “VM Dependency Restart Condition Timeout”. So does this time-out apply to “Restarts Priority” or does it apply to “Restart Dependency” or maybe both? The answer is simple, this only applies to “Restart Priority”. Restart Dependency is a rule, a hard rule, a must rule, which means there’s no time-out. We wait until all VMs are restarted when you use restart dependency. Yes, the UI is confusing as the option mentions “dependency” where it should really talk about “priority”. I have reported this to engineering and PM, and hopefully it will be fixed in one of the upcoming releases.