There are many enhancements in vSphere 6.5, an overhaul of Storage IO Control is one of them. In vSphere 6.5 Storage IO Control has been reimplemented by leveraging the VAIO framework. For those who don’t know VAIO stands for vSphere APIs for IO Filtering. This is basically a framework that allows you to filter (storage) IO and do things with it. So far we have seen caching and replication filters from 3rd party vendors, and now a Quality of Service filter from VMware.
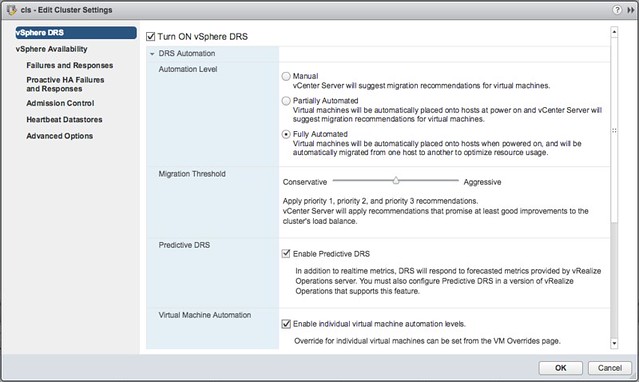
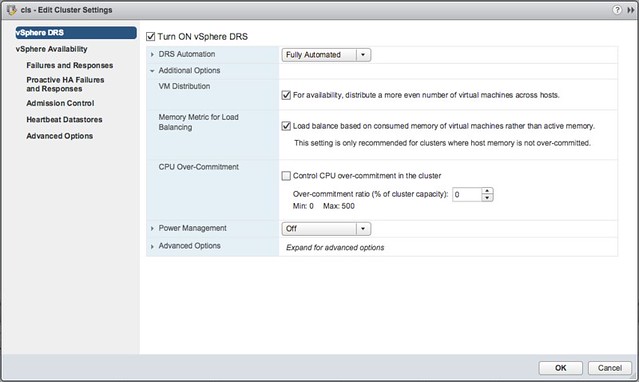
Storage IO Control has been around for a while and hasn’t really changed that much since its inception. It is one of those features that people take for granted and you actually don’t know you have turned on in most cases. Why? Well Storage IO Control (SIOC) only comes in to play when there is contention. When it does come in to play it ensure that every VM gets its fair share of storage resources. (I am not going to explain the basics, read this posts for more details.) Why the change in SIOC design/implementation? Well fairly simple, the VAIO framework enabled policy based management. This goes for caching, replication and indeed also QoS. Instead of configuring disks or VMs individually, you will now have the ability to specify configuration details in a VM Storage Policy and assign that policy to a VM or VMDK. But before you do, make sure you enable SIOC first on a datastore level and set the appropriate latency threshold. Lets take a look at how all of this will work:
- Go to your VMFS or NFS Datastore and right click datastore and click “Configure SIOC” and enable SIOC
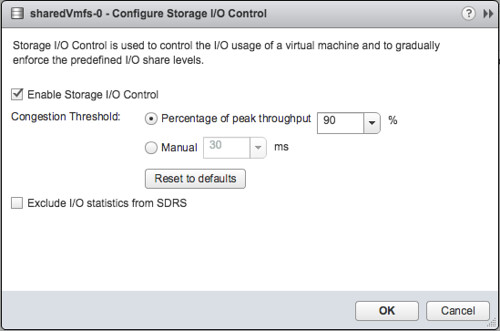
- By default the congestion threshold is set to 90% of peak throughput you can change this percentage or specify a latency threshold manually by defining the number of miliseconds latency
- Now go to the VM Storage Policy section
- Go to Storage Policy Components section first and check out the pre-created policy components, below I show “Normal” as an example
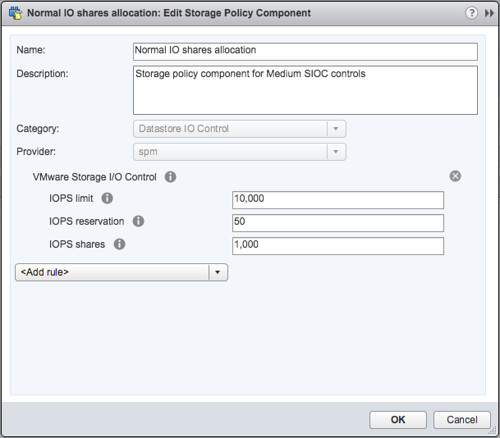
- If you want you can also create a Storage Policy Component yourself and specify custom shares, limits and a reservation. Personally I would prefer to do this when using SIOC and probably remove the limit if there is no need for it. Why limit a VM on IOPS when there is no contention? And if there is contention, well then SIOC shares based distribution of resource will be applied.
- Next you will need to do is create a VM Storage Policy, click that tab and click “create VM storage policy”
- Give the policy a name and next you can select which components to use
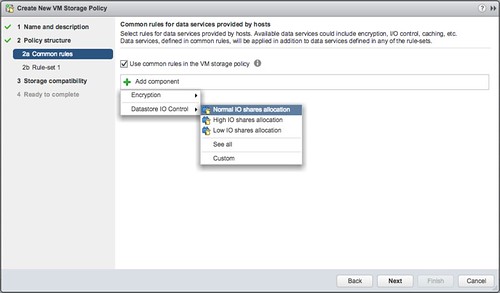
- In my case I select the “Normal IO shares allocation” and I also add Encryption, just so we know what that looks like. If you have other data services, like replication for instance, you could even stack those on top. That is what I love about the VAIO Framework.
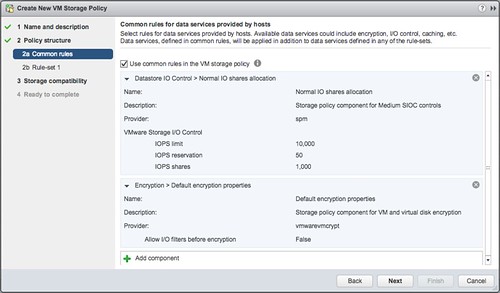
- Now you can add rules, I am not going to do this. And next the compatible datastores will be presented and that is it.
- You can now assign the policy to a VM. You do this by right clicking a particular VM and select “VM Policies” and then “Edit VM Storage Policies”
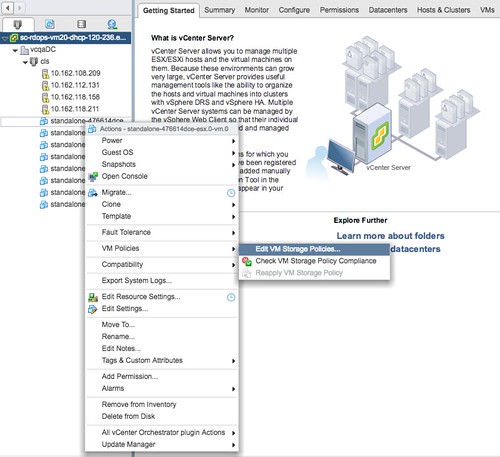
- Now you can decide which VM Storage Policy to apply to the disk. Select your policy from the dropdown and then click “apply to all”, at least when that is what you would like to do.
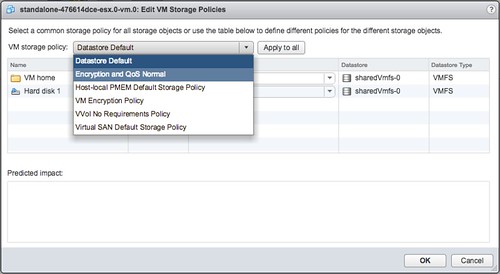
- When you have applied the policy to the VM you simply click “OK” and now the policy will be applied to the VM and for instance the VMDK.
And that is it, you are done. Compared to previous versions of Storage Policy Based Management this may all be a bit confusing with the Storage Policy Components, but believe me it is very powerful and it will make your life easier. Mix and match whatever you require for a workload and simply apply it.
Before I forget, note that the filter driver at this point is used to enforce limits only. Shares and the Reservation still leverages the mClock scheduler.

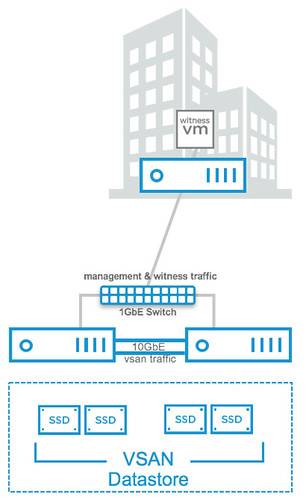 Next up on the list is 2-node direct connect. What does this mean? Well it basically means you can now cross-connect two VSAN hosts with a simple ethernet cable as shown in the diagram in the right. Big benefit of course is that you can equip your hosts with 10GbE NICs and get 10GbE performance for your VSAN traffic (and vMotion for instance) but don’t incur the cost of a 10GbE switch.
Next up on the list is 2-node direct connect. What does this mean? Well it basically means you can now cross-connect two VSAN hosts with a simple ethernet cable as shown in the diagram in the right. Big benefit of course is that you can equip your hosts with 10GbE NICs and get 10GbE performance for your VSAN traffic (and vMotion for instance) but don’t incur the cost of a 10GbE switch.