Here we go, one of my favourite features in vSphere… What’s new for HA in vSphere 6.5. To be honest, a lot! Many new features have been introduced, and although it took a while, I am honoured to say that many of these features are the results of discussions I had with the HA engineering team in the past. On top of that, your comments and feedback on some of my articles about HA futures have resulted in various changes to the design and implementation, my thanks for that! Before we get started, one thing I want to point out, in the Web Client under “Services” it now states “vSphere Availability” instead of HA, the reason for this is that because a new feature was stuck in to this section which is all about Availability but not implemented through HA.
- Admission Control
- Restart Priority enhancements
- HA Orchestrated Restart
- ProActive HA
Lets start with Admission Control first. This has been completely overhauled from a UI perspective, but essential still offers the same functionality but in an easy way and some extras. Let take a look at the UI first and then break it down.
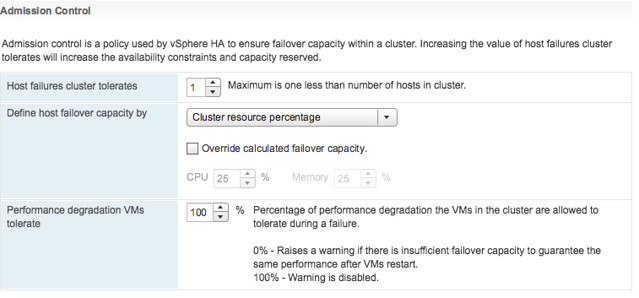
In the above screenshot we see “Cluster Resource Percentage” while above that we have specified the “Host failures cluster tolerates” as “1”. What does this mean? Well this means that in a 4 host cluster we want to be capable of losing 1 host worth of resources which equals 25%. The big benefit of this is that when you add a host to the cluster, the amount of resources set aside will then be automatically changed to 20%. So if you scale up, or down, the percentage automatically adjusts based on the selected number of failures you want to tolerate. Very very useful if you ask me as you won’t end up wasting resources any longer simply because you forgot to change the percentage when scaling the cluster. And the best, this doesn’t use “slots” but is the old “percentage based” solution still. (You can manually select the slot policy under “Define host failover capacity by” though if you prefer that.
Second part of enhancements around Admission Control is the “VM resource reduction event threshold” section. This is a new section and this is based on the fling that was out there for a while. I am very proud to see this being released as it is a feature I was closely involved with and actually had two patents awarded for recently. What does it do? It allows you to specify the performance degradation you are willing to incur if a failure happens. It is set to 100% by default, but I can imagine you want to change this to for instance 25% or 50%, depending on your SLA with the business. Setting it is very simple, you just change the percentage and you are done. So how does this work? Well first of all, you need DRS enabled as HA leverages DRS to get the cluster resource usage. But lets look at an example:
75GB of memory available in 3 node cluster
1 host failure to tolerate specifed
60GB of memory actively used by VMs
0% resource reduction tolerated
This results in the following:
75GB – 25GB (1 host worth of memory) = 50GB
We have 60GB of memory used, with 0% resource reduction to tolerate
60GB needed, 50GB available after failure >> Warning issued to Admin
Very useful if you ask me, as finally you can guarantee that the performance for you workloads after a failure event is close or equal to the performance before a failure event! Next up, Restart Priority enhancements. We have had this option in the UI for the longest time. It allowed you to specify the startup priority for VMs and that is what HA used during scheduling, however the restarts would happen so fast that in reality no one really noticed the difference between high, medium or low priority. In fact, in many cases the small “low priority” VMs would be powered up long before the larger “high priority” database machines. With 6.5 we introduce some new functionality. Lets show you how this works:
Go to your vSphere HA cluster and click on the configure tab and then select VM Overrides, next click Add. You are presented with a screen where you can select VMs by clicking the green plus and then specify their relative startup priority. I selected 3 VMs and then pick “lowest”, the other options are “low, medium, high and highest”. Yes the names are a bit funny, but this is to ensure backwards compatibility with the previous priority options.
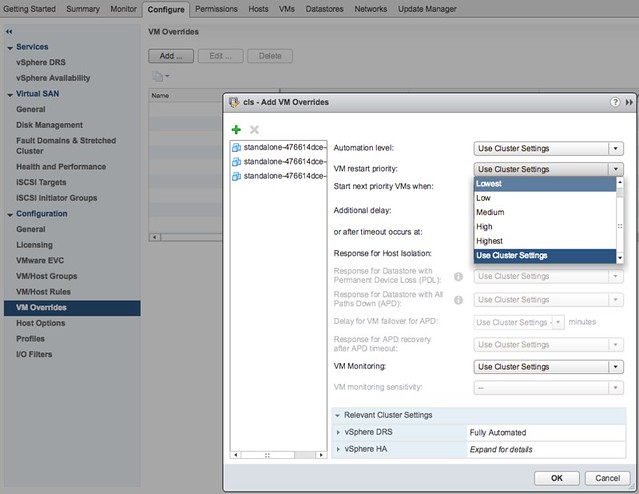
After you have specified the priority you can also specify if there needs to be an additional delay before the next batch can be started, or you can specify even what triggers the next priority “group”, this could for instance be the VMware Tools guest heartbeat as shown in the screenshot below. The other option is “resources allocated” which is purely the scheduling of the batch itself, the power-on event completion or the “app heartbeat” detection. That last one is most definitely the most complex as you would need to have App HA enabled and services defined etc. I expect that if people use this they will mostly set it to “Guest Heartbeats detected” as that is easy and pretty reliable.
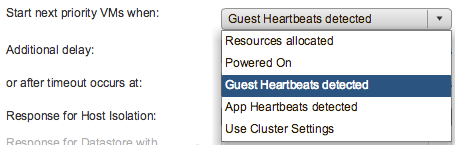
If for whatever reason by the way there is no guest heartbeat ever, or it simply takes a long time then there is also a timeout value that can be specified. By default this is 600 seconds, but this can be decreased or increased, depending on what you prefer. Now this functionality is primarily intended for large groups of VMs, so if you have a 1000 VMs you can select those 10/20 VMs that have the highest priority and let them power-on first. However, if you for instance have a 3-tier app and you need the database server to be powered on before the app server then you can also use VM/VM rules as of vSphere 6.5, this functionality is referred to as HA Orchestrated Restart.
You can configure HA Orchestrated Restarts by simply creating “VM” Groups. In the example below I have created a VM group called App with the Application VM in there. I have also created a DB group with the Database VM in there.
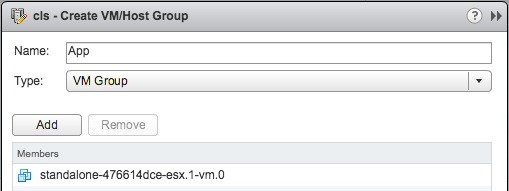
This application has a dependency on the Database VM to be fully powered-on, so I specify this in a rule as shown in the below screenshot.
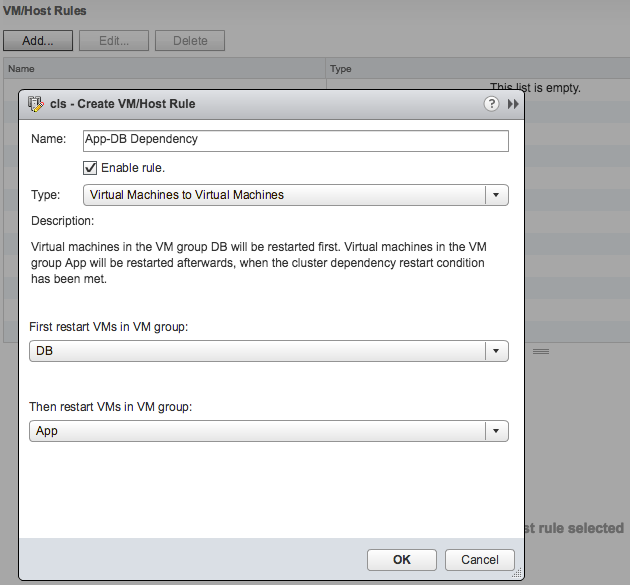
Now one thing to note here is that in terms of dependency, the next group of VMs in the rule will be powered on when the cluster wide set “VM Dependency Restart Condition” is met. If this is set to “Resources Allocated”, which is the default, then the VMs will be restarted literally a split second later. So you will need to think about how to set the “VM Dependency Restart Condition” as other wise the rule may be useless. Another thing is that these rules are “hard rules”, so if the DB VM in this example does not power on, then the App VM will also not be powered on. Yes, I know what you would like to see, and yes we are planning more enhancements in this space.
Last up “Pro-Active HA“… Now this is the odd one, it is not actually a vSphere HA feature, but rather a function of DRS. However, as it is stuck in the “Availability” section of the UI I figured I would stick it in this article as that is probably where most people will be looking. So what does it do? Well in short, it allows you to configure actions for events that may lead to VM downtime. What does that mean? Well you can imagine that when a power-supply goes down your host is in a so called “degraded state”, when this event occurs an evacuation of the host could be triggered, meaning all VMs will be migrated to any of the remaining healthy hosts in the cluster.
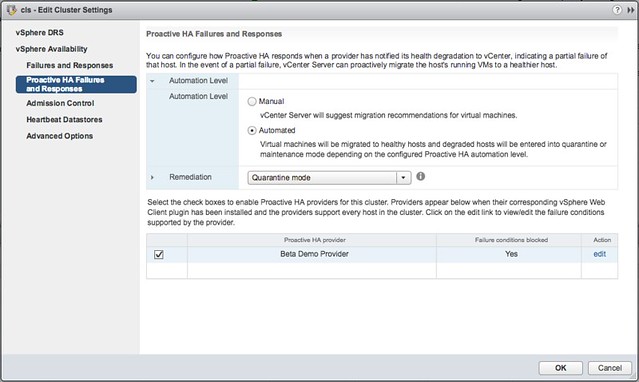
But how do we know the host is in a degraded state? Well that is where the Health Provider comes in to play. The health provider reads all the sensor data and analyze the results and then serve the state of the host up to vCenter Server. These states are “Healthy”, “Moderate Degration”, “Severe Degradation” and “Unknown”. (Green, Yellow, Red) When vCenter is informed DRS can now take action based on the state of the hosts in a cluster, but also when placing new VMs it can take the state of a host in to consideration. The actions DRS can take by the way is placing the host in Maintenance Mode or Quarantine Mode. So what is this quarantine mode and what is the difference between Quarantine Mode and Maintenance Mode?
Maintenance Mode is very straight forward, all VMs will be migrated off the host. With Quarantine Mode this is not guaranteed. If for instance the cluster is overcommitted then it could be that some VMs are left on the quarantined host. Also, when you have VM-VM rules or VM/Host rules which would conflict when the VM is migrated then the VM is not migrated either. Note that quarantined hosts are not considered for placement of new VMs. It is up to you to decide how strict you want to be, and this can simply be configured in the UI. Personally I would recommend setting it to Automated with “Quarantine mode for moderate and Maintenance mode for sever failure(Mixed)”. This seems to be a good balance between up time and resource availability. Screenshot below shows where this can be configured.

Pro-Active HA can respond to different types of failures, at the start of this section I mentioned power supply, but it can also respond to memory, network, storage and even a fan failure. Which state this results in (severe or moderate) is up to the vendor, this logic is built in to the Health Provider itself. You can imagine that when you have 8 fans in a server that the failure of one or two fans results in “moderate”, whereas the failure of for instance 1 out of 2 NICs would result in “severe” as this leaves a “single point of failure”. Oh and when it comes to the Health Provider, this comes with the vendor Web Client plugins.
Hi Duncan,
Excellent Article thanks for the information.
Regarding the same context i have a doubt about the Reservations with SRM.
The Protected Cluster in the recovery site reserves the CPU & MEM.
Situation
Site A Protected site
Site B Recovery site
4 Vms of Cluster 1/Site A are protected in Cluster 1 Site B
When we see the “Resource allocation” of Cluster 1 in Site B i can see there are
reservations set automatically, because there are no reservations on the VM.
From where did the reservation come.
I found that apart from Placeholders Cluster 1 of Site B also have few powered on VM`s.
So its a mix of Powered on Vms & Place holders, but no body has set any reservation on any VM.
Can you help to identify this mystery as i didnt find any documentation on this.
Thanks,
Jomon
Hello Duncan,
What is the best admission control policy for a 2 hosts cluster for your opinion?
I would always go for percentage based, just easier in general…
Hello Duncan, any thoughts on what “VM resource reduction event threshold” should be configured with an vMSC? The admission cotnrol policy percentage based is used and is configured to override failover capacity and then reservers 50% CPU and RAM.
I think it makes sence to configure “VM resource reduction event threshold” to 0 because you want a warning if the failover capacity in a vMSC is nog guaranteed.
What do you think? And will this feature work properly with a vMSC?
Can you confirm that descriptions in WebClient for HA Isolation response actions are correct?
1. Disabled – No action will be taken on the affected VMs.
2. Shutdown and restart VMs – All affected hosts will be gracefully shutdown and vSphere HA will attempt to restart the VMs on hosts that are still online.
3. Power off and restart VMs – All affected hosts will be powered off and vSphere HA will attempt to restart the VMs on hosts that still have network connectivity.
For Disabled setting it is clear, both host and VMs will stay powered on. But it is little confusing what happens with hosts in case that we choose option 2 or 3? First it clearly says that VMs will be shutdown (or powered off) and restarted, but further description is making confusion. It says that affected hosts will be shutdown (or powered off) and then VMs will be restarted.
So, VMs are going to be restarted anyway if we choose option 2 or 3, but is it correct that isolated host will be shutdown (or powered off) if we set options 2 or 3?
HI Duncan,
if i isolate VCHA network, VC failover takes place where as if i try to isolate the management network of Active node no fail over happens and the VC remains not accessible by the user !