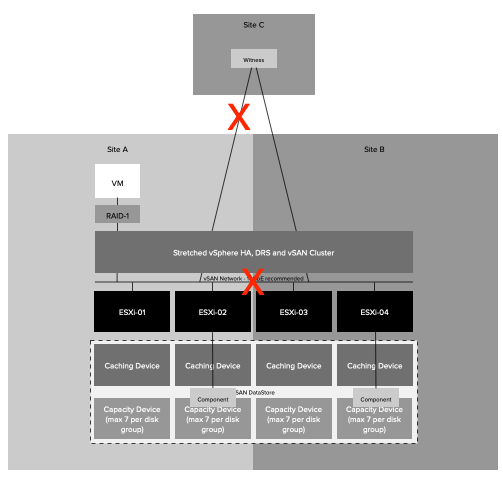
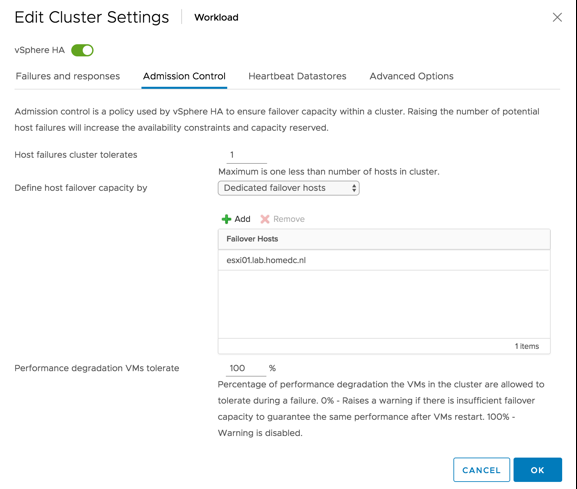
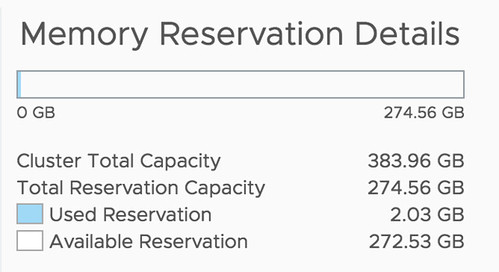
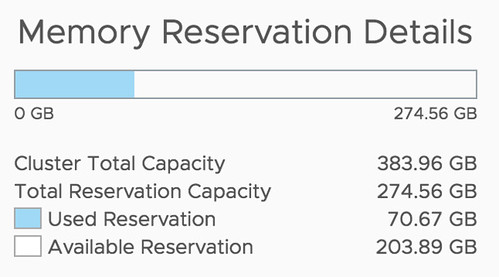
At VMworld, various cool new technologies were previewed. In this series of articles, I will write about some of those previewed technologies. Unfortunately, I can’t cover them all as there are simply too many. This article is about enhancements in the business continuity/disaster recovery space. There were 2 sessions where futures were discussed, namely HCI2894BU and HBI3109BU. Please note that this is a brief summary of those sessions, and these are discussing a Technical Preview, these features/products may never be released, and these previews do not represent a commitment of any kind, and this feature (or it’s functionality) is subject to change. Now let’s dive into it, what can you expect for disaster recovery in the future?
The first session I watched was HCI2894BU, this was all about Site Recovery Manager. I think the most interesting part is the future support for Virtual Volumes (vVols) for Site Recovery Manager. It may sound like something simple, but it isn’t. When the version of SRM ships that supports vVols keep in mind that your vVol capable storage system also needs to support it. At day 1 HPe Nimble, HPe 3PAR and Pure Storage will support it and Dell EMC and NetApp are actively working on support. The requirements are that the storage system needs to be vVols 2.0 compliant and support VASA 3.0. Before they dove into the vVols implementation, some history was shared and the current implementation. I found it interesting to know that SRM has over 25.000 customers and has protected more than 3.000.000 workloads over the last decade.