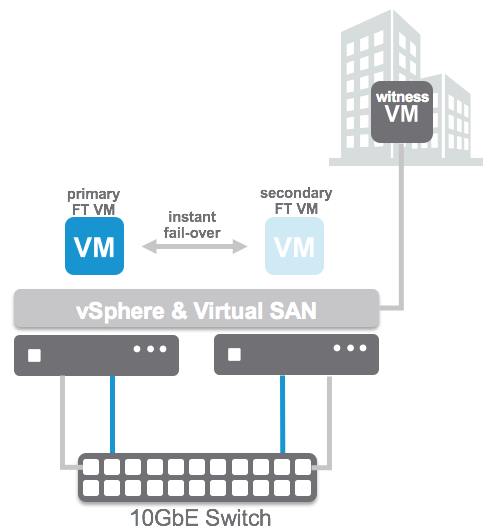
Last week at VMworld when presenting on Virtual SAN Stretched Clusters someone asked me if it was possible to “disable the fail-over of VMs during a full site failure while allowing a restart during a host failure”. I thought about it and said “no, that is not possible today”. Yes you can “disable HA restarts” on a per VM basis, but you can’t do that for a particular type of failure.
The last statement is correct, HA does not allow you to disable restarts for a site failure. You can fully disable HA for a particular VM though. But when back at my hotel I started thinking about this question and realized that there is a work around to achieve this. I didn’t note down the name of the customer who asked the question, so hopefully you will read this.
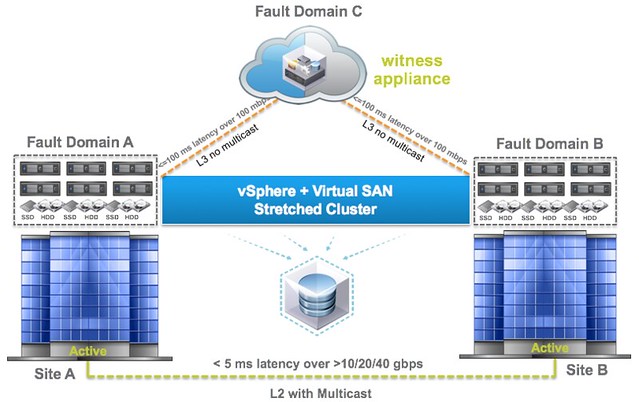
When it comes to a stretched cluster configuration typically you will use VM/Host rules. These rules will “dictate” where VMs will run, and typically you use the “should” rule as you want to make sure VMs can run anywhere when there is a failure. However, you can also create “must” rules, and yes this means that the rules will not be violated and that those VMs can only run within that site. If a host fails within a site then the impacted VMs will be restarted within the site. If the site fails then the “must rule” will prevent the VMs from being restarted on the hosts in the other location. The must rules are pushed down to the “compatibility list” that HA maintains, which will never be violated by HA.
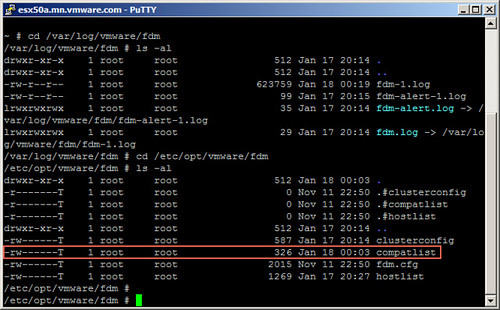
Simple work-around to prevent VMs from being restarted in another site.