This question is going to come sooner or later, how do I configure HA/DRS when I am running a Virtual SAN Stretched cluster configuration. I described some of the basics of Virtual SAN stretched clustering in a what’s new for 6.1 post already, if you haven’t read it then I urge you to do so first. There are a couple of key things to know, first of all the latency between data sites that can be tolerated is 5ms and to the witness location ~100ms.
If you look at the picture you below you can imagine that when a VM sits in Fault Domain A and is reading from Fault Domain B that it could incur a latency of 5ms for each read IO. From a performance perspective we would like to avoid this 5ms latency, so for stretched clusters we introduce the concept of read locality. We don’t have this in a non-stretched environment, as there the latency is microseconds and not miliseconds. Now this “read locality” is something we need to take in to consideration when we configure HA and DRS.
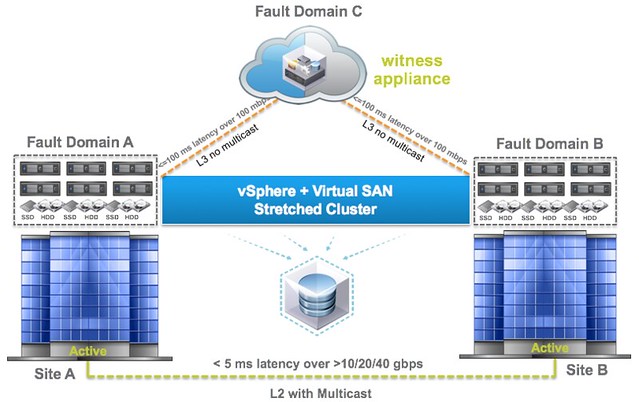
When it comes to vSphere HA the configuration is straight forward. We need to ensure we have a “local” isolation address for both “active data sites”, so that in the case a site partition occurs and one of the hosts is isolated we know it can ping a local address. This can simply be achieved by adding the following advanced settings to vSphere HA:
- das.isolationaddress0 = 192.168.1.1
- das.isolationaddress1 = 192.168.2.1
When you do this I would also recommend disabling the use of the default gateway as an isolation address. You can simply do this by setting the following advanced setting:
- das.useDefaultIsolationAddress=false
So far, straight forward. The Isolation Response I would recommend to set to “power off and restart VM“. Main reason for it being that the chances are extremely high that when the HA network is isolated that your storage (VSAN) network is also isolated and the VM won’t be able to access its disk any longer.
I also would recommend to configure HA to respect the VM/Host affinity rules. This can simply be done in the UI these days, the option is called “Respect VM to Host affinity rules during failover”. Make sure this is enabled. And of course there is Admission Control. Make sure that it is set to 50% for CPU and 50% for memory, anything lower than that means you risk VMs not being restarted during a full-site-failure. Note that it is no resource guarantee, just a restart guarantee!
Next stop, DRS. DRS configuration is straight forward, it can be configured to “fully automated“. In order to ensure that you do not incur a max of 5ms latency for a read, we highly recommend to implement VM/Host should rules for each of the sites. Create a group for each site with all the hosts in that particular site, and do the same for the other site. Now make a grouping for the VMs which will be tied to those sites, 50% of the VMs in each of the sites respectively. Also, make sure that when you define the rule it is a “should” rule. A “must” rule will not be violated, and that can result in an unpleasant situation when you need to do a full site fail-over. When there is a full site failure or a partition and the failures has been lifted, I would recommend placing the DRS configuration to “partially automated” during the outage so that VMs are not migrated back during the “resynchronisation” stage when the failure has been resolved. I would prefer to move them back after resyncing has been completed. Note that when you migrate the VMs back to the original site, the cache will need to be rewarmed, and as such I would prefer to migrate the VMs during maintenance hours. Although the performance impact won’t be huge, and I can also see why people would want to move back to the original site as soon as it is up, it is no requirement so that is up to you to decide.
All fairly straight forward and very similar to the vMSC configuration for 6.x. Only thing that is different is that with Virtual SAN you don’t configure VM Component Protection, which is something you need to do for vMSC. All in all, VSAN Stretched Clustering is fairly straight forward, and can literally be configured in minutes, and that includes HA and DRS!
Great material Duncan, I attended your stretched cluster session at VMworld and I am super excited that I finally have an alternative to the NetApp metrocluster’s that we pay out the nose for at my company. Our environment is pretty small, around 300 VM’s – Exchange, SQL, Full VDI clones, Linked clones, aggregate IOPS ranges from 2500-6000 IOPS. Would you recommend putting a mixed workload like that onto a VSAN cluster? All the material I’ve seen has demonstrated separating VDI and Server workloads onto their own VSAN cluster.
Not sure how this will work from a licensing/EULA standpoint to be honest. As far as I know the Horizon EULA doesn’t allow you to mix workloads.
Also for an environment that experiences frequent whole-site maintenance would you recommend a minimum 8 node (4+4+1) cluster?
Depends on how many VMs you have, the type/amount of resource they consume etc. I mean it could be 2+2+witness, which during a site failure is 2+witness. Or even 15+15+witness, difficult to say. But I would suspect most customers deploying this will be 4+4+witness at a minimum.
Thanks for sharing this. Really appreciate!
Hi Duncan,
Why does the witness need 100 mbs as per the diagram? That seems a bit excessive.
Also Simon was talking about the new auto read locality feature over at http://www.mrvsan.com/virtual-san-stretched-cluster/
Does this not negate the need for DRS host-affinity rules as VMs will no longer have a home/preferred site from a storage point of view, as it would with NetApp MetroCluster and EMC VPLEX, as it will be automatically set?
Many thanks
Mark
100Mbps is average, but will of course depend on how many VMs you are running. Keep in mind that although the witness is used for metadata, depending on the type of VMs this still could be significant.
With regards to DRS rules, the “local cache” doesn’t migrate with the VM. So you want the DRS rules to keep the VMs site local. That way you always use the cache. If it happens to migrate to a different site then you will need to rewarm the cache.
Say I want to run the 4 nodes in Site A at 65% total usage but Site B only ever runs at like 15%, I theoretically have enough capacity for a full site failure either way. Does Admission Control and/or DRS take any of this into consideration that there is an imbalanced load between those hosts even though the cluster is well within operating efficiencies and can handle a full site failure?
Depends if their is an imbalance big enough to trigger DRS to migrate VMs. When you have VM/Host affinity rules set up correctly you prevent this balancing from happening, balancing then can only happen within the site instead of across etc.
SIOC and Stretched cluster / Metro CLuster, whats really supported? Seems to be a lot of different answers depending on the storage supplier? Old post from you stated some info regarding vplex, Is there any resources regarding this?
http://kb.vmware.com/selfservice/microsites/search.do?cmd=displayKC&docType=kc&externalId=2042596&sliceId=1&docTypeID=DT_KB_1_1&dialogID=873915051&stateId=0%200%20873917463
Hi Duncan,
Having a lot of problems trying to get an External VSAN witness appliance recognised in the 2 node VSAN stretched cluster – I can add it in as a stretched cluster node fine, however VCSA shows ‘Found 0 witness hosts on stretched cluster – The number should be 1’. I have set up static routes as per the recommendations from both esxi boxes to the witness appliance VSAN network and back, and all boxes can ping the VSAN IPs from each other (using vmkping on the command line).
Please could you provide some hints on how to set up the routing for a stretched cluster where the VSAN Witness Appliance is hosted on a 3rd party network? I can’t see any examples online, however this should be a fairly standard practice?
Many thanks indeed.
Duncan Baxter
Did you contact support about this? This should work just fine.
No I am trying to build the solution proof-of-concept in the lab on the trial licenses before purchasing the VSAN advanced license…. It worked fine when the witness node was on the same /24 subnet, but as soon as I move the witness VSAN network to a different subnet and add in the static routes, it can’t be found in the cluster, which worries me a little! It’s as if the VSAN is trying to do multicast still, but of course it won’t be able to as the witness is routed over L3. Is there anything that has to be done to tell VSAN/VCSA that the witness is off-network and routed?
Many thanks
I have not tested this (in terms of re’iping a witness)… but it should work. Assuming you have the Witness VM outside of the cluster and the VSAN VMkernel interface can be pinged using the VSAN VMKernel from one of the other hosts?
Hi Duncan,
The witness is outside of the cluster in a separate ‘vsan-witness-cluster’ and has been added into VCSA, however it won’t allow me to add it in to the stretched cluster config. Just says ‘Can not complete the operation – See the event log for details’ Not sure which event log I should look at.
The two ESXi machines can ping the witness VSAN IP, and the Witness can ping the VSAN IPs of both ESXi boxes, so I’m a little confused! 🙁 I’ll keep digging!!….
Just a quick update for anyone that may find this useful, I got this stretched cluster with nested witness appliance working over Layer 3 – The critical point here is that the VSAN networks required static routes with a gateway on the same VSAN network (Not out via the management interface).
Thanks for the heads up.
Excellent as usual.
Hello,
I’ve configured a VSAN stretched cluster configuration with 2 datahosts en 1 witness host over 3 different sites. The 2 datahosts are on the same subnet with IP 192.168.0.1/24 for datahost 1 and 192.168.0.2/24 for datahost 2. There is only one default gateway for this VLAN (192.168.0.254/24). It’s a layer 2 configuration between the datahosts and a routable L3 configuration to the witness site. How can I configure this setup over L2 for the das.isolationaddress0 and das.isolationaddress1?
Thanks.
If you only have 1 gateway address and no other reliable physical site local device with an IP then you don’t have many options to be honest.