Last week I was talking to one of our developers at our R&D offsite. He has a situation where he saw his VM flip flopping between two hosts when he was testing a certain failure scenario and he wondered why that was. In his case he had a 2 node cluster connected to vCenter Server and a bunch of VMs running on just 1 host. All of the VMs were running off iSCSI storage. When looking at vCenter he literally would see his VMs on host 1 and a split second later on host 2, and this would go on continuously. I have written about this behaviour before, but figured it never hurts to repeat it as not everyone goes back 2-3 years to read up on certain scenarios.
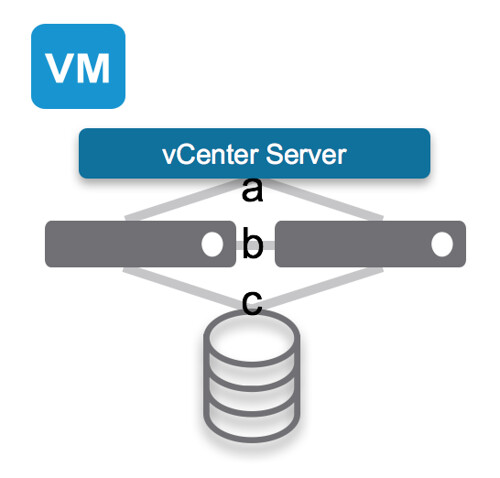
In the above diagram you see a VM running on the first host. vCenter Server is connected to both hosts through Network A and the Datastore being used is on Network C and the host management network is connected through Network B. Now just imagine that Network B is for whatever reason gone. The hosts won’t be able to ping each other any longer. In this case although it is an isolation, the VMs will have access through the central datastore and depending on how the isolation response is configured the VMs may or may not be restarted. Either way, as the datastore is still there, even if isolation response is set to “disabled” / “leave powered on” the VM will not be restarted on the second host as the “VM” is locked through that datastore, and you cannot have 2 locks on those files.
Now if simultaneously Network B and C are gone, this could potentially pose a problem. Just imagine this to be the case. Now the hosts are able to communicate to vCenter Server, however they cannot communicate to each other (isolation event will be triggered if configured), and the VM will lose access to storage (network C is down). If no isolation event was configured (disabled or leave powered on) then the VM on the first host will remain running, but as the second host has noticed the first host is isolated and it doesn’t see the VM any longer and the lock on those files are gone it is capable of restarting that VM. Both hosts however are still connected to vCenter Server and will send their updates to vCenter Server with regards to the inventory they are running… And that is when you will see the VM flip flopping (also sometimes referred to as ping-ponging) between those hosts.
And this, this is exactly why:
- It is recommend to configure an Isolation Response based on the likelihood of a situation like this occurring
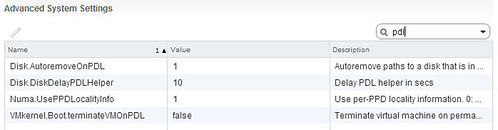
- If you have vSphere 6.0 and higher, you should enable APD/PDL responses, so that the VM running on the first host will be killed when storage is gone.
I hope this helps…