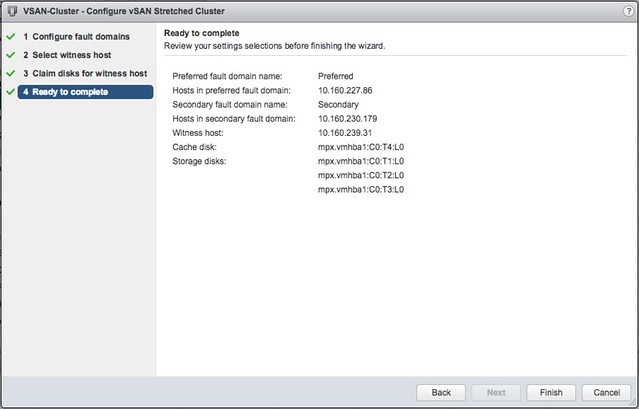
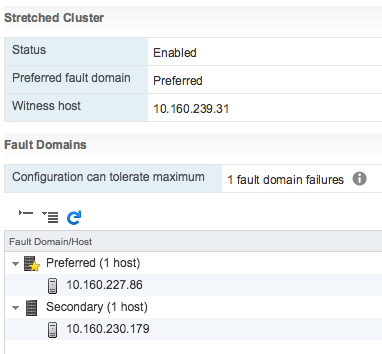
I have been having discussions with various customers about all sorts of highly available vSAN environments. Now that vSAN has been available for a couple of years customers are starting to become more and more comfortable around designing these infrastructures, which also leads to some interesting discussions. Many discussions these days are on the subject of multi room or multi site infrastructures. A lot of customers seem to have multiple datacenter rooms in the same building, or multiple datacenter rooms across a campus. When going through these different designs one thing stands out, in many cases customers have a dual datacenter configuration, and the question is if they can use stretched clustering across two rooms or if they can do fault domains across two rooms.
Of course theoretically this is possible (not supported, but you can do it). Just look at the diagram below, we cross host the witness and we have 2 clusters across 2 rooms and protect the witness by hosting it on the other vSAN cluster:
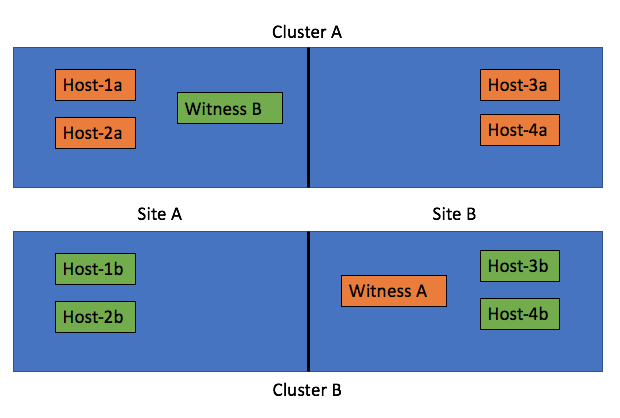
The challenge with these types of configurations is what happens when a datacenter room goes down. What a lot of people tend to forget is that depending on what fails the impact will vary. In the scenario above where you cross host a witness the failure if “Site A”, which is the left part of the diagram, results in a full environment not being available. Really? Yeah really:
- Site A is down
- Hosts-1a / 2a / 1b / 2b are unavailable
- Witness B for Cluster B is down >> as such Cluster B is down as majority is lost
- As Cluster B is down (temporarily), Cluster A is also impacted as Witness A is hosted on Cluster B
- So we now have a circular dependency
Some may say: well you can move Witness B to the same side as Witness A, meaning in Site B. But now if Site B fails the witness VMs are gone also impacting all clusters directly. That would only work if only Site A is ever expected to go down, who can give that guarantee? Of course the same applies to using “fault domains”, just look at the diagram below:
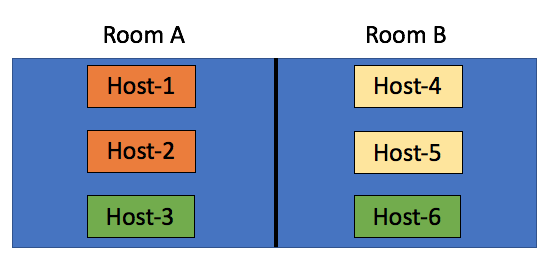
In this scenario we have the “orange fault domain” in Room A, “yellow” in Room B and “green” across rooms as there is no other option at that point. If Room A fails, VMs that have components in “Orange” and on “Host3” will be impacted directly, as more than 50% of their components will be lost the VMs cannot be restarted in Room B. Only when their components in “fault domain green” happen to be on “Host-6” then the VMs can be restarted. Yes in terms of setting up your fault domains this is possible, this is supported, but it isn’t recommended. No guarantees can be given your VMs will be restarted when either of the rooms fail. My tip of the day, when you start working on your design, overlay the virtual world with the physical world and run through failure scenarios step by step. What happens if Host 1 fails? What happens if Site 1 fails? What happens if Room A fails?
Now so far I have been talking about failure domains and stretched clusters, these are all logical / virtual constructs which are not necessarily tied to physical constructs. In reality however when you design for availability/failure, and try to prevent any type of failure to impact your environment the physical aspect should be considered at all times. Fault Domains are not random logical constructs, there’s a requirement for 3 fault domains at a minimum, so make sure you have 3 fault domains physically as well. Just to be clear, in a stretched cluster the witness acts as the 3rd fault domain. If you do not have 3 physical locations (or rooms), look for alternatives! One of those for instance could be vCloud Air, you can host your Stretched Cluster witness there if needed!