I just finished writing the vMSC 6.0 Best Practices paper which is about to be released when a question came in. The question was around the APD scenario and whether the response to an APD should be set to aggressive or conservative. Its a good question and my instinct immediately say: conservative… But should it be configured to that in all cases? If so, why on earth do we even have an aggressive method? That got me thinking. (By the way, make sure to read this article by Matt Meyer on VMCP on the vSphere blog, good post!) But before I spill the beans, what is aggressive/conservative in this case, and what is this feature again?

VM Component Protection (VMCP) is new in 6.0 and it allows vSphere to respond to a scenario where the host has lost access to a storage device. (Both PDL and APD.) In previous releases, vSphere was already capable of responding to PDL scenarios but the settings weren’t really exposed in the UI and that has been done with 6.0 and the APD response has also been added at the same time. Great feature if you ask me, especially in stretched environments as it will help during certain failure scenarios.
But what happens exactly when disaster strikes and an APD has occurred? When an APD condition is detected a timer is started. After 140 seconds the APD condition is officially declared and the device is marked as APD time out. (Note that this is configurable, the minimum value for Misc.APDTimeout is 20 seconds) When the 140 seconds has passed HA will start counting, the default HA time out is 3 minutes. When the 3 minutes have passed HA VMCP can restart the impacted virtual machines, depending on how you configured it of course. There are three different responses that you can set it to:
- Disabled
- Issue events
- Power off and restart VMs (conservative)
- Power off and restart VMs (aggressive)
I think that “Disabled” and “Issue events” speak for itself, but what does “conservative” and “aggressive” mean? Conservative and Aggressive refers to the likelihood of HA being able to restart VMs. When set to “conservative” HA will only kill the VM that is impacted by the APD if it knows another host can restart it. In the case of “aggressive” HA will always kill the VM even if it doesn’t know the state of the other hosts, which could lead to a situation where your VM is not restarted as there is no host that has access to the datastore the VM is located on.
The question then comes when do you use conservative and when do you use aggressive? Well, first of all, let me say that by far “conservative” is the safest approach and for ‘regular’ environments (not stretched) I would probably always recommend using “conservative”, but there are of course use cases for aggressive as well. I would start by asking these questions first:
- If you are using a stretched cluster, is it a “uniform” or “non-uniform” config?
- What is the likelihood of an APD scenario occurring to your storage devices on ALL of your hosts at the same time versus some hosts?
- Do you have VM to Host rules set up for your VMs and what is the likelihood of VMs sitting on the wrong side of the partition?
As stated, I would probably recommend “conservative” for non-stretched environments. For stretched the above questions come in to play. For “non-uniform” environments an APD is very uncommon, but for uniform, it is more common. So if you have a uniform configuration and it is unlikely that the APD happens on all hosts within your cluster (which usually is uncommon) then the third question determines how you should configure this setting. If you have VM to Host rules configured then it is unlikely a VM will reside in the wrong side and as such when an APD occurs (site partition for instance) it is unlikely that a VM is impacted as it is running on the side of the cluster that has an affinity with datastore. If you do not have VM/Host rules configured then VMs could be all over the place and it would be best to configure this setting to aggressive so that VMs are killed instantly and can be restarted without the risk of having 2 instances running at the same time. SAY WHAT? Yes, I realize this is fairly complex, let’s draw it out and describe it step by step.
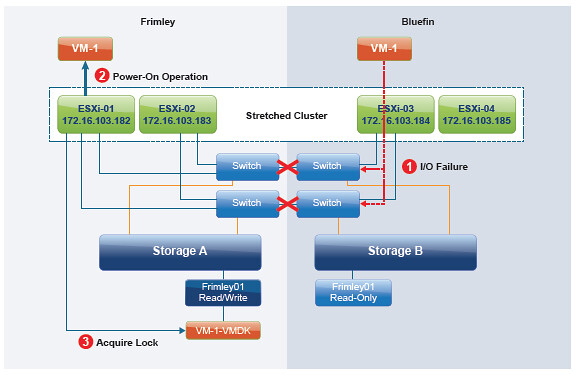
- This environment is using a uniform configuration, meaning that ALL hosts are connected to ALL storage systems.
- VM-1 is running in location “Bluefin”, however storage affinity is with location “Frimley”
- A site partition occurs and hosts within Bluefin lose access to “Storage A” and datastore “Frimley01” ends up in an “APD” state for “ESXi-03” and “ESXi-04”
- ESXi-01 and ESXi-02 still have access to Storage A and datastore Frimley01 and will restart VM-1
- Although ESXi-03 and ESXi-04 have lost access to Frimley01 they will only kill VM-1 when:
- VM Component Protection is configured and APD response is set to “aggressive”
The reason for this is that in a full partition hosts on either side cannot talk to each other and as such ESXi-03 and ESXi-04 don’t know if ESXi-01 and ESXi-02 will be capable of restarting VM-1. If the APD response is configured to “conservative” then you will have an instance of VM-1 running in Frimley and one in Bluefin. The one in Bluefin of course will not have access to the datastore, which prevents data corruption from happening and other bad things. Still, having two instances with the same name / ip-address running is never a good thing. When APD response is set to aggressive then this situation can be avoided.
As you can see, this is one of those settings that only truly makes sense in very specific scenarios and with specific configurations. So before you make a decision, think it through!
Duncan, awesome article, thank you.
One question, I understand why one would use the aggressive setting in uniform stretched clusters when no VM-Host rules exist, but I cant think of a reason why set a uniform stretched cluster without setting vm-host rules? I would think that it is common sense to set these rules every time to prevent cross sites storage communication and to prevent ghost VMs.
Niran
Agreed, but I have seen plenty of folks not setting it as they prefer VMs to freely roam around… whether that is the right thing to do or not.
Interesting, free range metro clustering 🙂 thanks for the answer Duncan
Duncan, Thanks for these precious information,Does VMCP respond to Single Lun and VM (like Local datastores) PDL/APD scenarios?
As per My understanding,When the device is went into PDL/APD states,This is the best method
for recovering register VMs from this Path.
Uma.