Last week I was talking to a customer and they posed some interesting questions. What excites me in IT (why I work for VMware) and what is next for hyper-converged? I thought they were interesting questions and very relevant. I am guessing many customers have that same question (what is next for hyper-converged that is). They see this shiny thing out there called hyper-converged, but if I take those steps where does the journey end? I truly believe that those who went the hyper-converged route simply took the first steps on an SDDC journey.
Hyper-converged I think is a term which was hyped and over-used, just like “cloud” a couple of years ago. Lets breakdown what it truly is: hardware + software. Nothing really groundbreaking. It is different in terms of how it is delivered. Sure, it is a different architectural approach as you utilize a software based / server side scale-out storage solution which sits within the hypervisor (or on top for that matter). Still, that hypervisor is something you were already using (most likely), and I am sure that “hardware” isn’t new either. Than the storage aspect must be the big differentiator right? Wrong, the fundamental difference, in my opinion, is how you manage the environment and the way it is delivered and supported. But does it really need to stop there or is there more?
There definitely is much more if you ask me. That is one thing that has always surprised me. Many see hyper-converged as a complete solution, reality is though that in many cases essential parts are missing. Networking, security, automation/orchestration engines, logging/analytic engines, BC/DR (and orchestration of it) etc. Many different aspects and components which seem to be overlooked. Just look at networking, even including a switch is not something you see to often, and what about the configuration of a switch, or overlay networks, firewalls / load-balancers. It all appears not to be a part of hyper-converged systems. Funny thing is though, if you are going on a software defined journey, if you want an enterprise grade private cloud that allows you to scale in a secure but agile manner these components are a requirement, you cannot go without them. You cannot extend your private cloud to the public cloud without any type of security in place, and one would assume that you would like to orchestrate every thing from that same platform and have the same networking / security capabilities to your disposal both private and public.
That is why I was so excited about the VMworld US keynote. Cross Cloud Services on top of hyper-converged leveraging all the tools VMware provides today (vSphere, VSAN, NSX) will exactly allow you to do what I describe above. Whether that is to IBM, vCloud Air or any other of the mega clouds listed in the slide below is even besides the point. Extending your datacenter services in to public clouds is what we have been talking about for a while, this hybrid approach which could bring (dare I say) elasticity. This is a fundamental aspect of SDDC, of which a hyper-converged architecture is simply a key pillar.
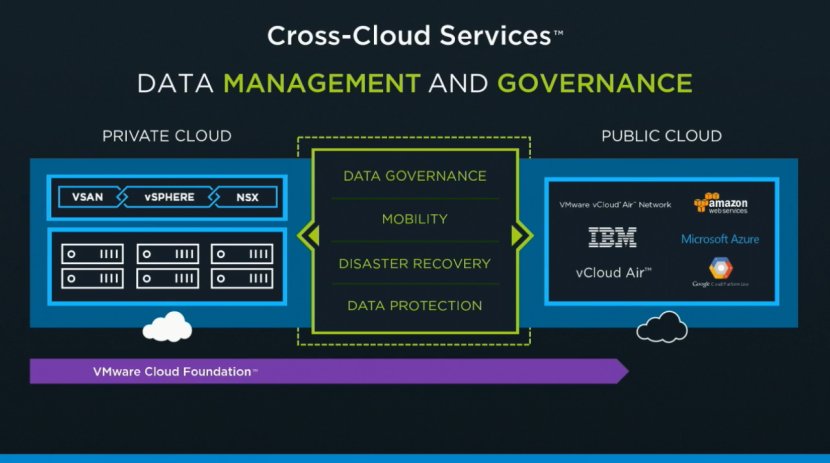
Hyper-converged by itself does not make a private cloud. Hyper-converged does not deliver a full SDDC stack, it is a great step in to the right direction however. But before you take that (necessary) hyper-converged step ask yourself what is next on the journey to SDDC. Networking? Security? Automation/Orchestration? Logging? Monitoring? Analytics? Hybridity? Who can help you reach full potential, who can help you take those next steps? That’s what excites me, that is why I work for VMware. I believe we have a great opportunity here as we are the only company who holds all the pieces to the SDDC puzzle. And with regards to what is next? Deliver all of that in an easy to consume manner, that is what is next!

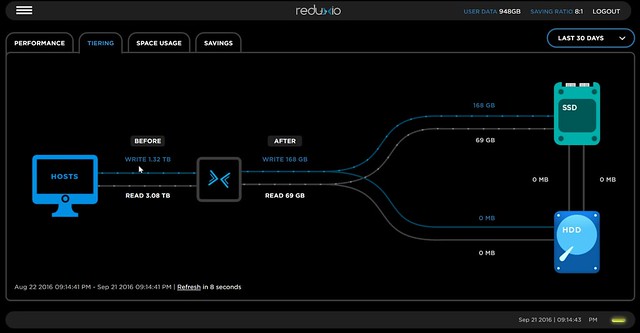
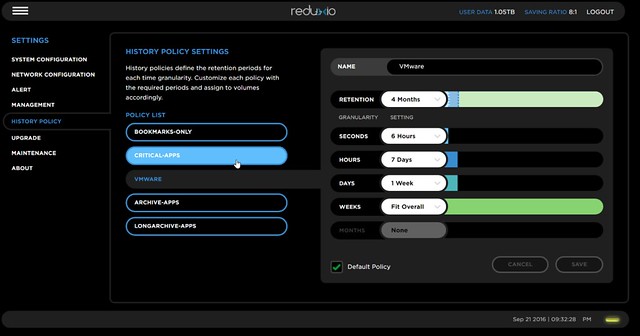
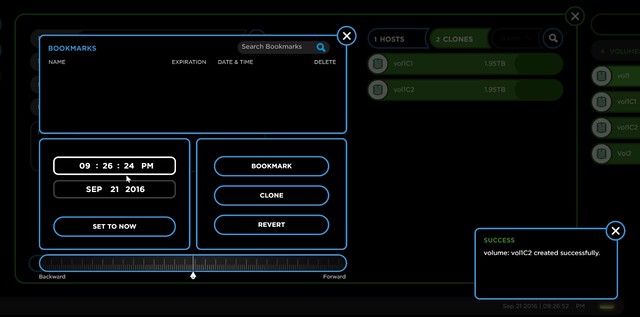

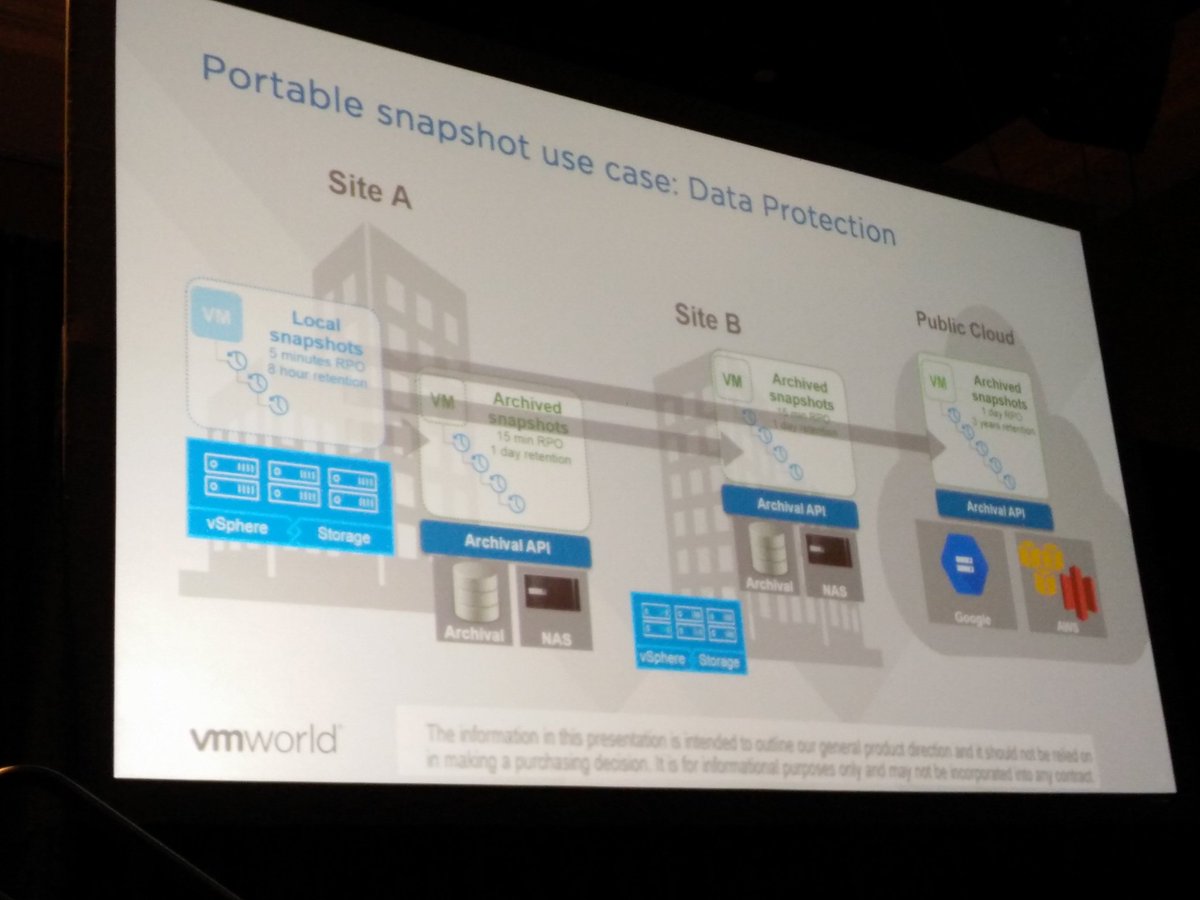
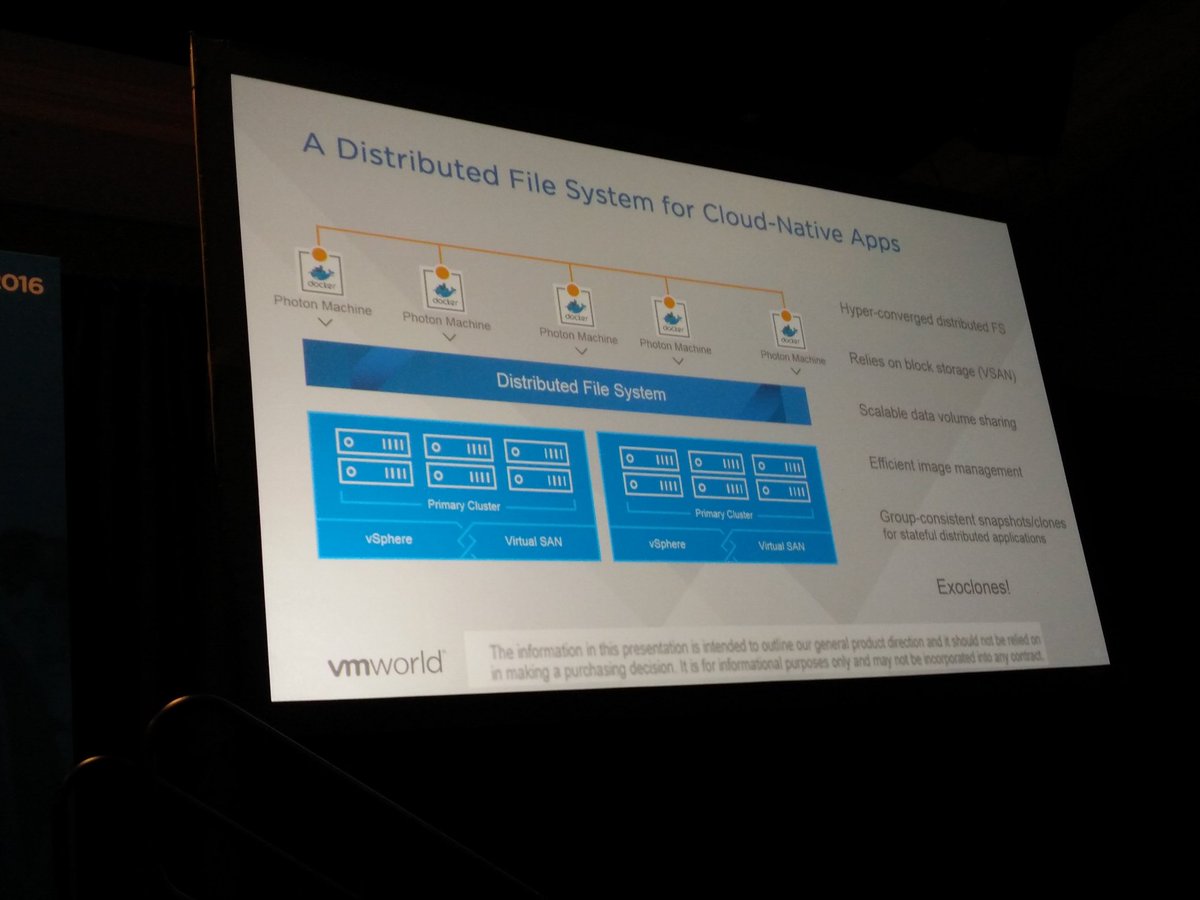
 After having gone through all holiday email it is now time to go over some of the briefings. The Rubrik briefing caught my eye as it had some big news in there. First of all, they landed Series C, big congrats, especially considering the size, $ 61m is a pretty substantial I must say! Now I am not a financial analyst, so I am not going to spend time talking too much about it, as the introduction of a new version of their solution is more interesting to most of you. So what did Rubrik announce with version 3 aka Firefly.
After having gone through all holiday email it is now time to go over some of the briefings. The Rubrik briefing caught my eye as it had some big news in there. First of all, they landed Series C, big congrats, especially considering the size, $ 61m is a pretty substantial I must say! Now I am not a financial analyst, so I am not going to spend time talking too much about it, as the introduction of a new version of their solution is more interesting to most of you. So what did Rubrik announce with version 3 aka Firefly.