![]() About a year ago my attention was drawn to a storage startup called Reduxio, not because of what they were selling (they weren’t sharing much at that point though even) but because two friends joined them, Fred Nix and Wade O’Harrow (EMC / vSpecialist fame). I tried to set up a meeting back then and it didn’t happen for whatever reason and it slipped my mind completely. Before VMworld Fred asked me if I was interested in meeting up and we ended up having an hour long conversation at VMworld with Reduxio’s CTO Nir Peleg and Jacob Cherian who is the VP of Product. This week we followed up that conversation with a demo, we had an hour scheduled but the demo was done in 20 minutes… not because it wasn’t interesting, but because it was that simple and intuitive. So who is Reduxio and what do they have to offer?
About a year ago my attention was drawn to a storage startup called Reduxio, not because of what they were selling (they weren’t sharing much at that point though even) but because two friends joined them, Fred Nix and Wade O’Harrow (EMC / vSpecialist fame). I tried to set up a meeting back then and it didn’t happen for whatever reason and it slipped my mind completely. Before VMworld Fred asked me if I was interested in meeting up and we ended up having an hour long conversation at VMworld with Reduxio’s CTO Nir Peleg and Jacob Cherian who is the VP of Product. This week we followed up that conversation with a demo, we had an hour scheduled but the demo was done in 20 minutes… not because it wasn’t interesting, but because it was that simple and intuitive. So who is Reduxio and what do they have to offer?
Reduxio is a storage company which was founded in 2012 and backed by Seagate Technology, Intel Capital, JVP and Carmel Ventures. I probably shouldn’t say storage company as they are more positioning themselves as a data management company, which makes sense if you know their roadmap. For those who care, Reduxio has a head office in San Francisco and an R&D site in Israel. Today Reduxio offers a hybrid storage system. The system is called HX550 and is a dual controller (active/standby) solution which comes in a 2U form factor with 8 SSDs and 16 HDDs, of course connected over 10GbE, dual power supply which also includes a cache protection unit for power failures. Everything you would expect from a storage system I guess.

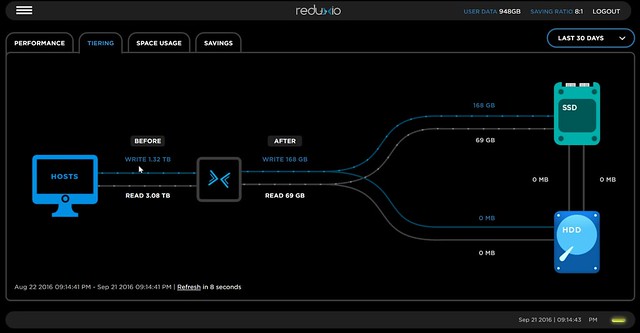
But the hardware specs are not what interested me. The features offered by the platform, or Reduxio’s TIME OS (as they call it) is what sets them apart from others. First of all, not surprisingly, the architecture revolves around flash. It is a tiering based architecture which provides in-memory deduplication and compression, this means that dedupe and compressions happens before data is stored on SSD or HDD. What I found interesting as well is that Reduxio expects IO to be random and all IO will go to SSD, however if it does detect sequential streams then the SSD is bypassed and the IO stream will go directly to HDD. This goes for both reads and writes by the way. Also, they take proximity of the data in to account when IO moves between SSD and HDD, very smart as that ensures data moves efficiently. All of this by the way, is shown in the UI of course, including dedupe/compression results etc.
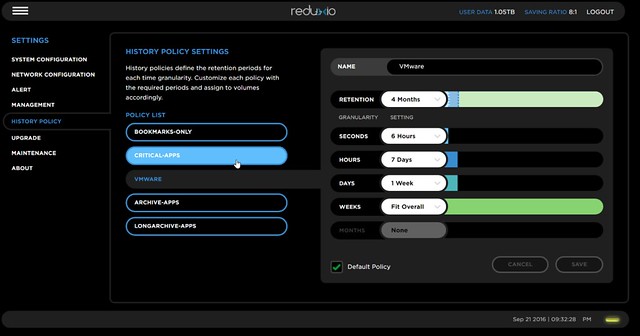
Now the interesting part is the “BackDating” feature Reduxio offers. Basically in their UI you can specify the retention time of data and automatically all volumes with the created policy will adhere to those retention times. You could compare it to snapshots, but Reduxio solved it differently. They asked themselves first what the outcome was a customer expected and then looked at how they could solve the problem, without taking existing implementations like snapshots in to account. In this case they added time as an attribute to a stored block. The screenshot below by the way shows how you can create BackDating policies and what you can set in terms of granularity. So “seconds” need to be saved for 6 hours in this example, hourly for 7 days and so on.
Big benefit is that as a result you can go to a volume and go back to a point in time and simply revert the volume to that point in time or create a clone from that volume for that point in time. This is also how the volume will be presented back to vSphere by the way, so you will have to re-signature it before you can access it. The screenshot below shows what the UI looks like, very straight forward, select a date / time or just use the slide if you need to go back seconds/minutes/hours.
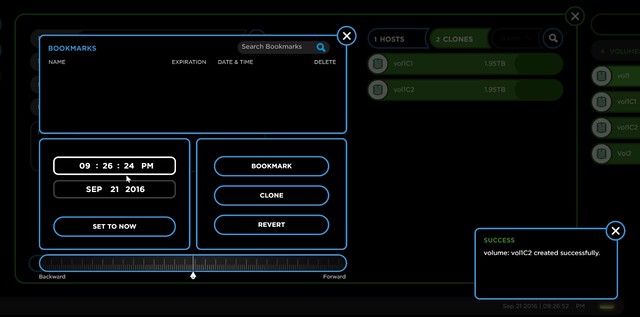
What struck me when they demoed this by the way was how fast these volume clones were created. Jacob, who was driving the demo, explained that you need to look at their system as a database. They are not creating an actual volume, the cloned volume seen by the host is more the result of a query where the data set consists of volume, offset, reference and time. Just a virtual construct that points to data.
Oh and before I forget, just to keep things simple the UI also allows you to set a bookmark for a certain point in time so that it is easier to go back to that point using your own naming scheme. Talking about the UI, I think this is the thing that impressed me most, it is a simple concept, but allowing you to drag and drop widgets in to your front page dashboard is something I appreciate a lot. I may want to see different info on the frontpage than someone else, having the ability to change this is very welcome. The other thing about their UI, it doesn’t feel crammed. In most cases with enterprise systems we seem to have the habit of cramming as much as we can on a single page which then usually results in users not knowing where to start. Reduxio took a clean slate approach, what do we need and what don’t we need?
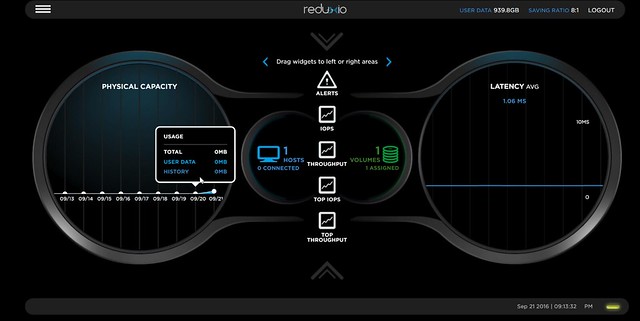
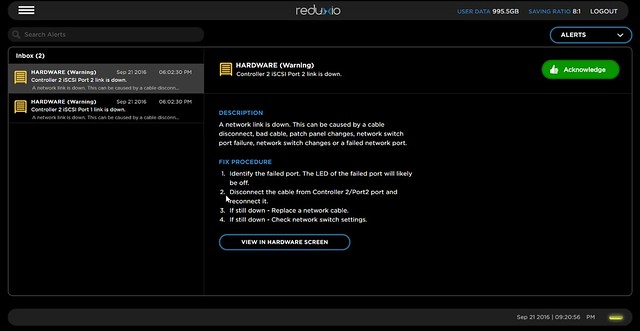
One other thing I liked was a feature they call StorSense. This is basically a SaaS based support infrastructure where analytics and an event database can help you prevent issues from occurring. When there is an error for instance the UI will inform you about the issue and also tells you how to mitigate it. Something which I felt was very useful as you don’t need to search an external KB system to figure out what is going on. Of course they also still offer traditional logging etc for those who prefer that.
That sounds cool right? So what’s the catch you may ask? Well there is one thing I feel is missing right now and that is replication. Or I should rather say the ability to sync data to different locations. Whether that is traditional sync replication or async replication or something in a different shape or form is to be seen. I am hoping they take a different approach again, as that is what Reduxio seems to be good at, coming up with interesting alternative ways for solving the same problem.
All in all they impressed me with what they have so far, and I didn’t even mention it, but they also have a vSphere plugin which allows for VM Level recovery. Hopefully we can expect support for VVols soon and some form of replication, just imagine how powerful that combination can be. Great work guys, and looking forward to hearing more in the future!
If you want to know more about them I encourage you to fill out their contact form so they can get back to you and give you a demo as I am sure you will appreciate it. (Or simply hit up someone like Fred Nix on twitter) Thanks Fred, Jacob and Nir for taking the time to have a chat!
It appears that folks are shying away from being a storage company, Reduxio would rather “positioning themselves as a data management company” than a storage company. And they aren’t the only ones.
Oh another storage venture with a few cool features but no major differentiation. How these companies keep getting funding is probably the real interesting bit.
I would say that the backdating alone sets them apart from many other storage companies.
I really enjoy the ‘Startup Intro’ feature of your blog Duncan, keep up the good work, I’d like to try something like this on my blog.
-Greg
“They asked themselves first what the outcome was a customer expected and then looked at how they could solve the problem, without taking existing implementations like snapshots in to account.” – THIS is what I call innovation 🙂
Great article but I agree with the above comments. I don’t see a anything that sets them apart from the mass amount of vendors in this market. Also; surely any storage vendor appearing on the scene should now be all flash? The other issue I see with this technology is that they are still running an active passive/standby controller? why are you limiting the performance. These days you should be using all the available hardware for performance and resilience (Active/Active) There is a lot of competition out there and you need to stand out from the crowd.
Hi Duncan, great intro!
can you say something about scale-ability? what happens after you run out of storage space? add a disk shelf? scale-out?