I was talking to a VMware partner over the past couple of weeks about challenges they had in a new vSphere Metro Storage Cluster (vMSC) environment. In their particular case they simulated a site partition. During the site partition three things were expected to happen:
- VMs that were impacted by APD (or PDL) should be killed by vSphere HA Component Protection
- If HA Component Protection does not work, vSphere should kill the VMs when the partition is lifted
- VMs should be restarted by vSphere HA
The problems faced were two-fold, VMs were restarted by vSphere HA, however:
- vSphere HA Component Protection did not kill the VMs
- When the partition was lifted vSphere did not kill the VMs which had lost the lock to the datastore either
It took a while before we figured out what was going on, at least for one of the problems. Lets start with the second problem first, why aren’t the VMs killed when the partition is lifted? vSphere should do this automatically. Well vSphere does this automatically, but only when there’s a Guest Operating system installed and an I/O is issued. As soon as an I/O is issued by the VM then vSphere will notice the lock to the disk is lost and obtained by another host and kill the VM. If you have an “empty VM” then this won’t happen as there will not be any I/O to the disk. (I’ve filed a feature request to kill VMs as well even without disk I/O or without a disk.) So how do you solve this? If you do any type of vSphere HA testing (with or without vMSC) make sure to install a guest OS so it resembles real life.
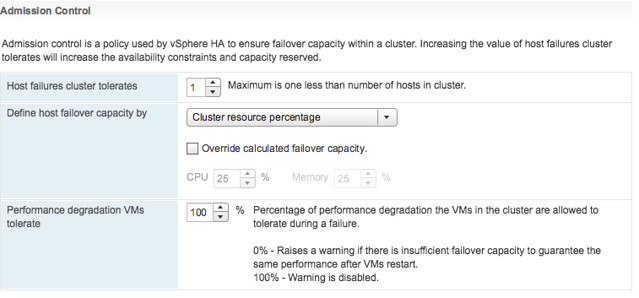
Now back to the first problem. The fact that vSphere HA Component Protection does not kick in is still being debated, but I think there is a very specific reason for it. vSphere HA Component Protection is a feature that kills VMs on a host so they can be restarted when an APD or a PDL scenario has occurred. However, it will only do this when it is:
- Certain the VM can be restarted on the other side (conservative setting)
- There are healthy hosts in the other partition, or we don’t know (Aggressive)
First one is clear I guess (more info about this here), but what does the second one mean? Well basically there are three options:
- Availability of healthy host: Yes >> Terminate
- Availability of healthy host: No >> Don’t Terminate
- Availability of healthy host: Unknown >> Terminate
So in the case you where you have VMCP set to “Aggressively” failover VMs, it will only do so when it knows hosts are available in the other site or when it does not know the state of the hosts in the other site. If for whatever reason the hosts are deemed as unhealthy the answer to the question if there are healthy hosts available or not will be “No”, and as such the VMs will not be killed by VMCP. The question remains, why are these hosts reported as “unhealthy” in this partition scenario, that is something we are now trying to figure out. Potentially it could be caused by misconfigured Heartbeat Datastores, but this is still something to be confirmed. If I know more, I will update this article.
Just received confirmation from development, heartbeat datastores need to be available on both sites for vSphere HA to identify this scenario correctly. If there are no heartbeat datastores available on both sites then it could happen that no hosts are marked as healthy, which means that VMCP will not instantly kill those VMs when the APD has occured.