As most of you probably know, vSAN File Services is not supported on a stretched cluster with vSAN 7.0 or 7.0U1. However, starting with vSAN 7.0 U2 we now fully support the use of vSAN File Services on a stretched cluster configuration! Why is that?
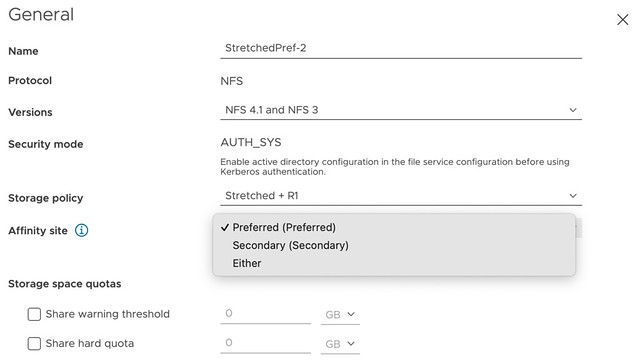
In 7.0 U2, you now have the ability to specify during configuration of vSAN File Services to which site certain IP addresses belong. In other words, you can specify the “site affinity” of your File Service services. This is shown in the screenshot below. Now I do want to note, this is a soft affinity rule. Meaning that if hosts, or VMs, fail on which these file services containers are running it could be that the container is restarted in the opposite location. Again, a soft rule, not a hard rule!

Of course, that is not the end of the story. You also need to be able to specify for each share with which location they have affinity. Again, you can do this during configuration (or edit it afterward if desired), and this basically then sets the affinity for the file share to a location. Or said differently, it will ensure that when you connect to file share, one of the file servers in the specified site will be used. Again, this is a soft rule, meaning that if none of the file servers are available on that site, you will still be able to use vSAN File Services, just not with the optimized data path you defined.
Hopefully, that gives a quick overview of how you can use vSAN File Services in combination with a vSAN Stretched Cluster. I created a video to demonstrate these new capabilities, you can watch it below.
Does this mean vSAN File Services is imminent for VMC on AWS? 🙂
I can’t talk about roadmap publicly 🙂
Hi Duncan.
Firstly, sorry for my poor english. I want to say : i love your job ! All is more simple with your explications !
I am testing vSANFS to replace “Windows” VMs that store VHDX container-profiles.
With vSANFS in 7u02, the Agent VMs are poweroff when the ESXi goes into maintenance mode. This stops access to the SMB service share for 60 – 90s! (ping loss for 20-30 seconds and Share availability for 60 – 90s).
It’s lot for the scheduled maintenance ! This it’s problem for apply the upgrade on a VxRail Cluster for example.
Why the Agent VM should not “vMotionized” on another host while this maintenance for minimized the service disruption ?
No worries about your english, it is good enough for me to understand the question 🙂
unfortunately that is not how it has been designed. It will indeed lead to a short disruption as the container which runs the file services needs to be restarted elsewhere. I can understand that this is not optimal and will ask the team if they are working on a way around this.
The vSANFS is progressing with each release and I hope the development teams are working on this because it is not usable in production.
An upgrade of my VxRail cluster can take 20-30 hours and if I use vSANFS, I can’t anticipate when the SMB service will be down. A maintenance mode should not disrupt the service like all other VMware features.
Thanks for your answer !
Duncan, hi :-), nice meeting you, thanks for all the posts you do on a daily basis… great info !
Let´s assume that I have a vSAN Streched Cluster in PROD, now I want to deploy File Services on top of it, my question is, is this an active-active Service ? I mean, based on SPBM I know I can stretched a file_share but, in case a NFS client (for example) is copying a file into this file_share and suddenly Site A power off, will I have a time out till File Services VMs restart in Site B or the Service will not be interrupted at all ? will this be transparent from the user side ? The same apply for SMB protocol or is different ?
Thanks !!
There’s no seamless failover capability. If a host fails, or site fails, the container facilitating that container that runs the file-services will be restarted elsewhere. This typically takes around 30 seconds.
Ok. What about having, let is say 4 containers – 2 per site – serving the same share in order to have redundancy. Is that possible? Thanks.
You connect to a share using 1 container… So if that container fails, you will reconnect in some shape or form and that just takes some time.