VMware Cloud Foundation 9.1 was just announced, and that means a lot of new functionality has been released. Some of the features you already knew about, others may come as a surprise. I know Pete Koehler has a whole series he is going to release, so I am just going to introduce a couple of features that I feel everyone should know about. Here’s a list of what was just announced:
- Native S3 Object Storage
- Cyber Recovery enhancements with Any to vSAN ESA, Seeding, Tag-Based VM selection and more
- Auto-RAID
- Global Deduplication and enhanced compression
- QLC support
- Mixed mode for Remote Datastores (ESA <-> OSA)
- Enhanced Capacity Reporting
- Resizing Shared VMDKs
Now, some of these capabilities I have been talking about for a while now at events, like Native S3 Object Storage, but it is probably still worth explaining what is announced. Let’s discuss a few of the above.
Native S3 Object Storage
This, in my opinion, is probably together with the Cyber Protection platform, the biggest feature that was announced for 9.1. Most of you probably use some kind of S3 Object Storage platform as a backup destination, or you may have developers (and apps) directly accessing an S3 bucket for various reasons. S3 Object Storage use cases and total capacity have exploded over the last decade. So far, we (VMware/Broadcom) have always partnered with 3rd party vendors to deliver these S3 capabilities on top of VCF, but more and more customers have asked for a well-integrated solution that would come as part of VCF. With an upcoming patch release of 9.1 the tech preview of Native S3 Object Storage will be released.
Although the platform has been referred to as “vSAN Native Object Storage” in the past, I feel it is more native to VCF. Although the configuration can be completed entirely through the API and CLI, most customers will likely consume the solution through VCF Automation. VCF Automation will provide the ability to have tenants (organizations) create their own S3 Object Storage Service (or even multiple), and have many buckets per S3 Object Storage Service. This will provide the logical isolation you would expect from a multi-tenancy platform. As a Provider Admin you simply enable S3 Object Storage for a region, and then each tenant who has resources in that region assigned can consume it and create the service, and subsequently buckets, as shown below.

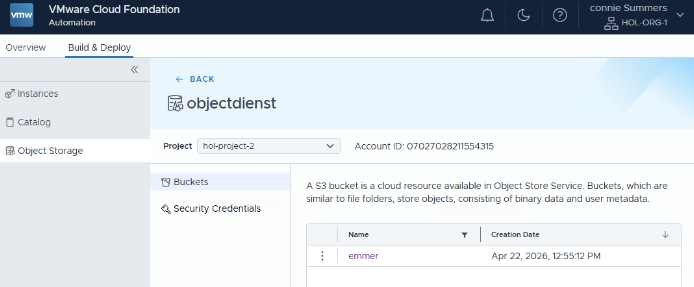
I will probably upload a demo soon and will record a podcast episode specifically on this topic.
Cyber Recovery
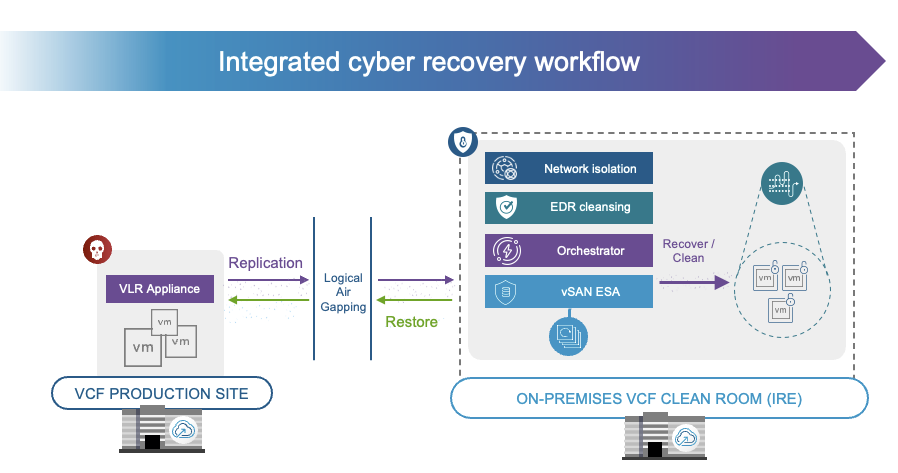
Recovery from a ransomware attack and protection against it, is a hot topic these days for every CIO. Just do a Google search, and you will find countless examples of companies losing millions as a result of production outages due to an attack. At Explore 2025, we showed the world what a sophisticated ransomware recovery platform would potentially look like, and with VCF 9.1 and Site Recovery / Cyber Recover, we are finally at the stage where we can say we have a solution to help you recover safely and efficiently fully on-prem!
With 9.1 not only do we provide the option to replicate from any storage platform efficiently to vSAN ESA and have deep snapshot chains, but we now also have the option to build an isolated recovery environment / clean room on-premises. This platform comes fully integrated with VCF, and provides an orchestrated workflow to recovery from a ransomware attack. On top of that, the platform integrates with an EDR solution like Carbon Black or CrowdStrike. to ensure recovered data is clean. Of course, it will also work with other EDRs, but it would just not have the automated scanning and cleaning just yet. I’ve had Jatin on the podcast not too long ago to explain all the benefits of the platform, and will be having another episode on this topic soon!
Global Dedupe and enhanced Compression
From an efficiency perspective, various new enhancements have been introduced. Global Deduplication was already part of vSAN ESA, but only available through a support request, as of 9.1 the feature is available for all customers right there in the UI. Along with Global Deduplication going GA, support for Encryption at Rest with Global Dedupe has also been added. For European customers, do note, support for stretched clusters is not there just yet, so some of you have to wait with enabling Global Dedupe. Besides Global Dedupe, a brand new compression algorithm has been added. In the past, compression was done using LZ4, going forward, compression will be done using zStandard. zStandard allows for better tuning, making it more capacity and cost (CPU) efficient, which should result in a higher compression ratio over time.
Auto-RAID and QLC
Last but not least, I should probably also briefly talk about QLC and Auto-RAID. QLC support is mainly intended for Cyber Recovery deployments. As you can imagine, this is the perfect use case for a lower-tier flash device, which provides high capacity at the cost of performance and endurance. This is something to definitely keep in mind, as these devices are definitely not intended to be used in regular production environment. As always, VMware will provide guidance in terms of what is supported and what not, and special Ready Node configurations will be created for Cyber Recovery specifically.
Auto-RAID is a feature that surprised me personally as well. I had heard about plans to develop a new RAID mechanism, but hadn’t realized it was going to ship in the 9.1 release already. This new storage policy option allows vSAN to make intelligent decisions around the to be used RAID configuration for each object based on the size of the cluster, and the features enabled on the cluster. In other words, if you have Stretched Cluster enabled, Auto-RAID will ensure your VMs are stretched and protect the VMs within a site accordingly, based on the number of hosts. If Auto-RAID is enabled, all 9.1 clusters can be managed using the same policy if you prefer vSAN to make the decisions for you! Why is this useful? Well, if the size of the cluster changes, or the cluster is (un)stretched, the Auto-RAID policy will automatically re-configure all associated VMs. This removes the risk of having VMs incorrectly configured and removes the administrative burden of having to make changes to a policy and re-apply it to all the VMs.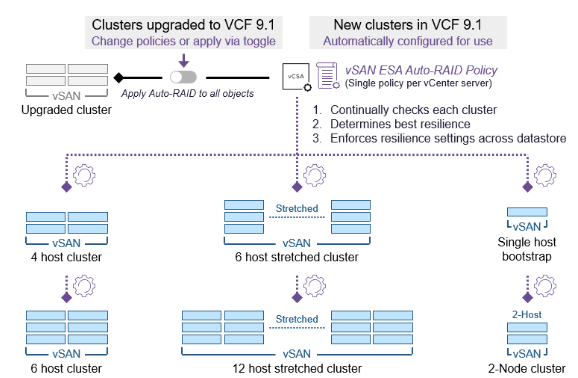
I have planned for a podcast recording with Pete Koehler later this week, so expect a brand new episode covering all the above (and more) dropping soon!
