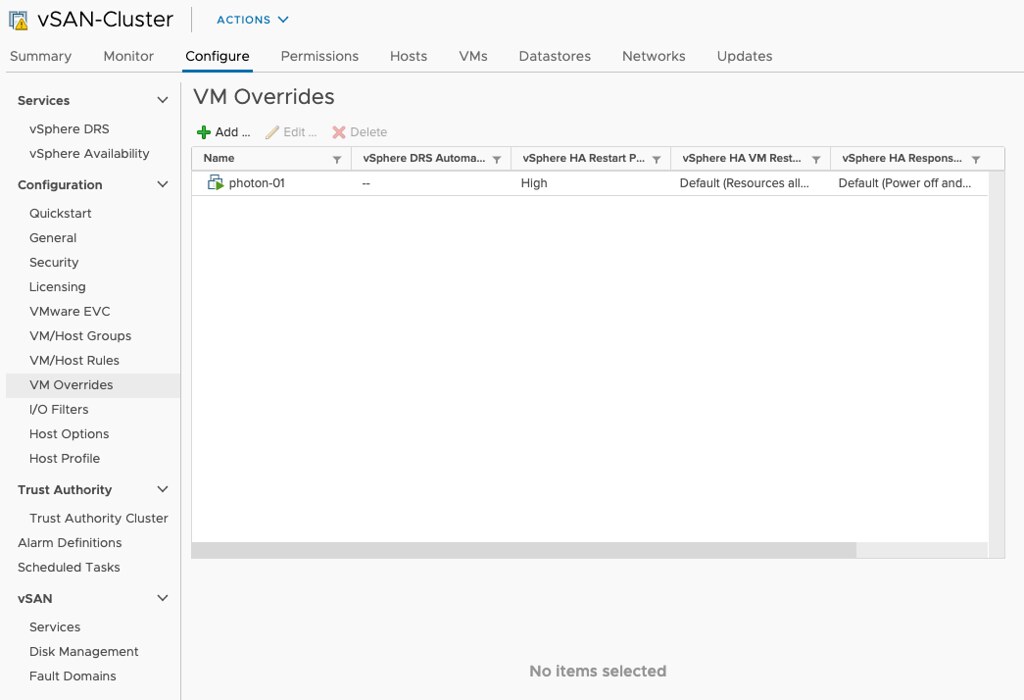
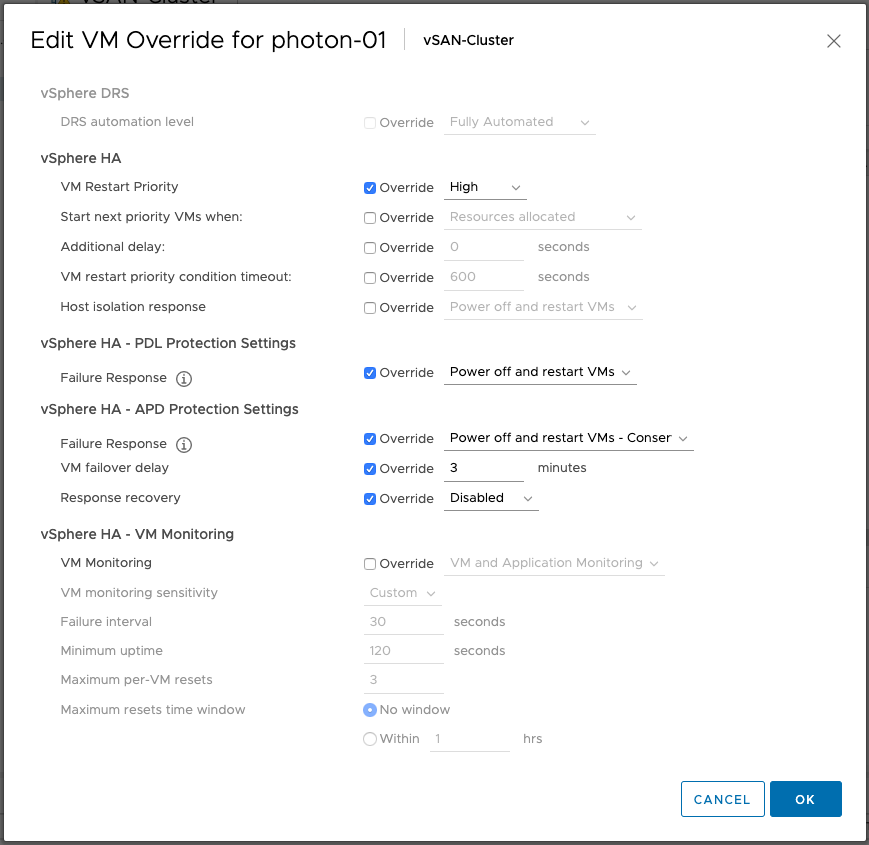
If you are running vSphere 6.7 or 6.5 and have not installed 6.7 P02 yet (6.5 P05 is available soon) and you have APD/PDL responses configured within vSphere HA it could be that an issue causes VMs not to be failed over when an APD or PDL occurs. This is a known issue in the release, and P02 or P05 solves this problem. What is the problem? Well, a bug causes VMs which are listed in “VM overrides” to have settings that are not configured to be set to “disabled” instead of “unset”, in specific the APD/PDL setting.
This means that even though you have APD/PDL responses configured on a cluster level, the VM level configuration overrides it as it would be set to “disabled”. It doesn’t matter really why you added them to VM Overrides, could be to configure VM Restart Priority for instance. The frustrating part is that the UI doesn’t show you it is disabled as it looks like it is not configured.
If you can’t install the patch just yet, for whatever reason, but you do have VMs in VM Overrides, make sure to go to VM Overrides and explicitly configure the VMs to have the APD/PDL responses enabled similar to what it is configured to on a cluster level as shown in the screenshots below.