I had a question today around how to safely remove a stretched VSAN configuration without putting any of the workloads in danger. This is fairly straight forward to be honest, there are 1 or 2 things though which are important. (For those wondering why you would want to do this, some customers played with this option and started loading workloads on top of VSAN and then realized it was still running in stretched mode.) Here are the steps required:
- Click on your VSAN cluster and go to Manage and disable the stretched configuration
- This will remove the witness host, but will leave 2 fault domains in tact
- Remove the two remaining fault domains
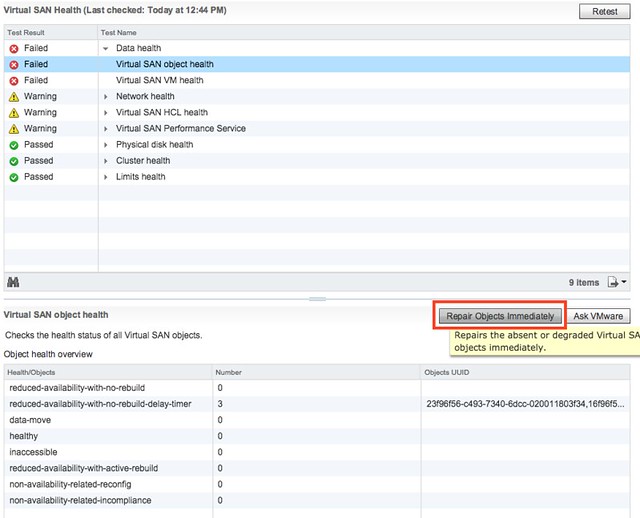
- Go to the Monitor section and click on Health and check the “virtual san object health”. Most likely it will be “red” as the “witness components” have gone missing. VSAN will repair this automatically by default in 60 minutes. We prefer to take step 4 though asap after removing the failure domains!
- Click “repair object immediately”, now witness components will be recreated and the VSAN cluster will be healthy again.
- Click “retest” after a couple of minutes
By the way, that “repair object immediately” feature can also be used in the case of a regular host failure where “components” have gone absent. Very useful feature, especially if you don’t expect a host to return any time soon (hardware failure for instance) and have the spare capacity.