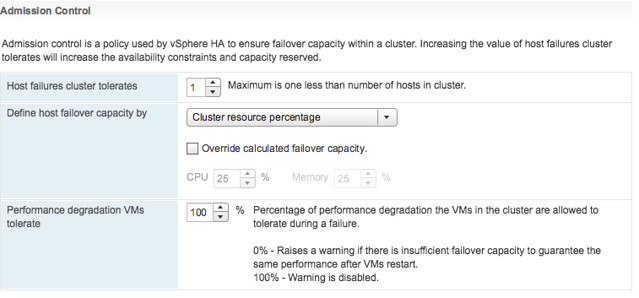
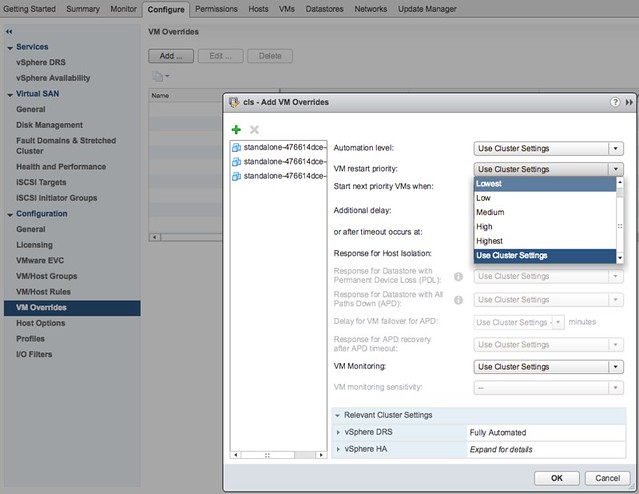
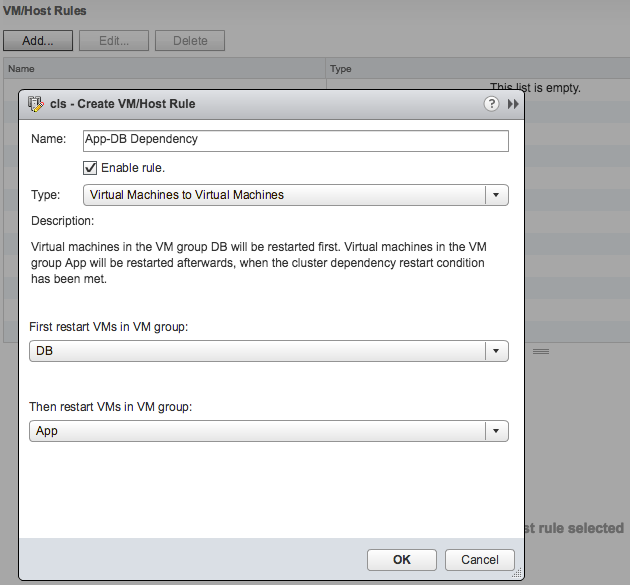
A couple of weeks ago one of our SEs asked me about vSphere HA functionality that was introduced a while ago, which is the ability to have HA disabled VMs being registered on other healthy hosts in a cluster after a failure. Not only does this apply to “HA disabled VMs” but also to powered-off VMs. This functionality was introduced to make it easier to power-on a VM after a host failure which was powered off before the failure, or which was disabled for HA restarts. Without this functionality you would need to re-register the VM on a different host, which are various unneeded steps.
The customer testing this scenario had noticed that whenever a failure occurred HA disabled, and powered off, VMs did not get registered. Strange as the documentation states the following:
“If a host fails, vSphere HA attempts to register to an active host the affected virtual machines that were powered on and have a restart priority setting of Disabled, or that were powered off.”
After talking to the vSphere HA engineers it was discovered that there was a bug in vSphere 6.0 U1 and U2. This bug resulted in the fact that HA disabled (or powered-off) VMs were not registered on other hosts. Very annoying. Fortunately, this problem has been solved in vSphere 6.0 U3. If you rely on this functionality to work correctly, please upgrade to vSphere 6.0 U3 to fix your problem. Thanks!