**disclaimer: Some of the content has been taken from the vSphere 5 Clustering Technical Deepdive book**
The first time I was playing around with 5.0 and particularly HA I noticed a new section in the UI called Datastore Heartbeating.
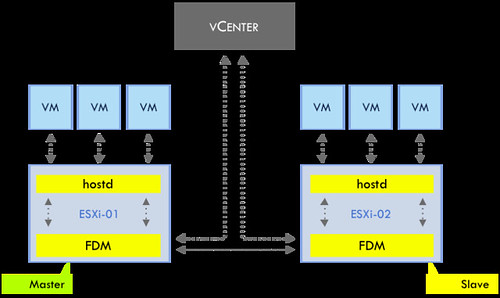
Those familiar with HA prior to vSphere 5.0 probably know that virtual machine restarts were always initiated, even if only the management network of the host was isolated and the virtual machines were still running. As you can imagine, this added an unnecessary level of stress to the host. This has been mitigated by the introduction of the datastore heartbeating mechanism. Datastore heartbeating adds a new level of resiliency and allows HA to make a distinction between a failed host and an isolated / partitioned host. Isolated vs Partitioned is explained in Part 2 of this series.
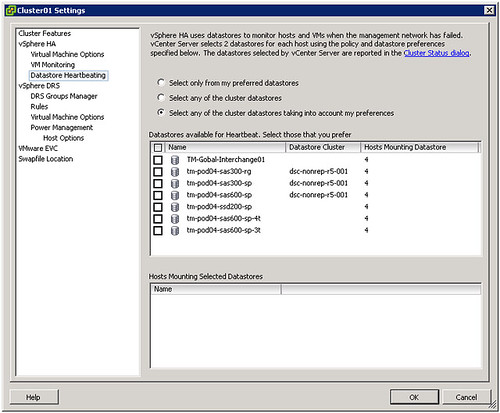
Datastore heartbeating enables a master to more correctly determine the state of a host that is not reachable via the management network. The new datastore heartbeat mechanism is only used in case the master has lost network connectivity with the slaves to validate whether the host has failed or is merely isolated/network partitioned. As shown in the screenshot above two datastores are automatically selected by vCenter. You can rule out specific volumes if and when required or even make the selection yourself. I would however recommend to let vCenter decide.
As mentioned by default it will select two datastores. It is possible however to configure an advanced setting (das.heartbeatDsPerHost) to allow for more datastores for datastore heartbeating. I can imagine this is something that you would do when you have multiple storage devices and want to pick a datastore from each, but generally speaking I would not recommend configuring this option as the default should be sufficient for most scenarios.
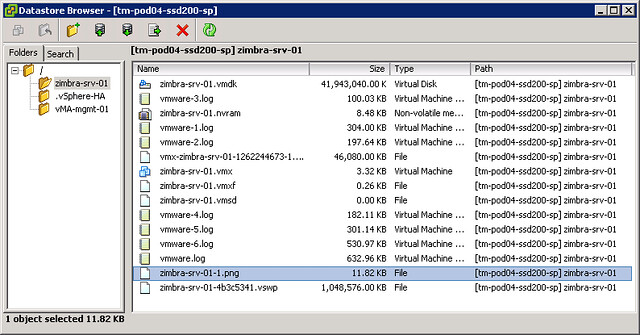
How does this heartbeating mechanism work? HA leverages the existing VMFS filesystem locking mechanism. The locking mechanism uses a so called “heartbeat region” which is updated as long as the lock on a file exists. In order to update a datastore heartbeat region, a host needs to have at least one open file on the volume. HA ensures there is at least one file open on this volume by creating a file specifically for datastore heartbeating. In other words, a per-host a file is created on the designated heartbeating datastores, as shown in the screenshot below. HA will simply check whether the heartbeat region has been updated.

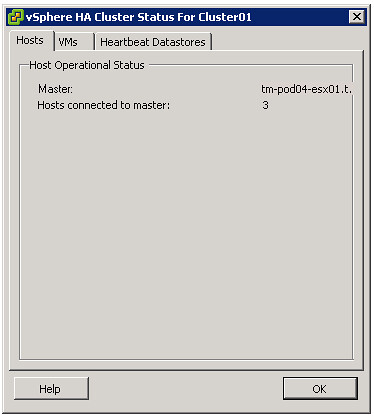
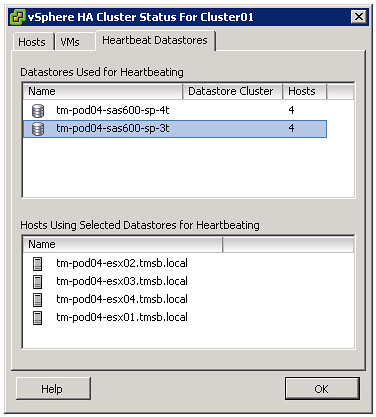
If you are curious which datastores have been selected for heartbeating. Just go to your summary tab on your cluster and click “Cluster Status”, the 3 tab “Heartbeat Datastores” will reveal it.
** Disclaimer: This article contains references to the words master and/or slave. I recognize these as exclusionary words. The words are used in this article for consistency because it’s currently the words that appear in the software, in the UI, and in the log files. When the software is updated to remove the words, this article will be updated to be in alignment. **