**disclaimer: Some of the content has been taken from the vSphere 5 Clustering Technical Deepdive book**
As mentioned in an earlier post vSphere High Availability has been completely overhauled… This means some of the historical constraints have been lifted and that means you can / should / might need to change your design or implementation.
What I want to discuss today is the changes around the Primary / Secondary node concept that was part of HA prior to vSphere 5.0. This concept basically limited you in certain ways… For those new to VMware /vSphere, in the past there was a limit of 5 primary nodes. As a primary node was a requirement to restart virtual machines you always wanted to have at least 1 primary node available. As you can imagine this added some constraints around your cluster design when it came to Blades environments or Geo-Dispersed clusters.
vSphere 5.0 has completely lifted these constraints. Do you have a Blade Environment and want to run 32 hosts in a cluster? You can right now as the whole Primary/Secondary node concept has been deprecated. HA uses a new mechanism called the Master/Slave node concept. This concept is fairly straight forward. One of the nodes in your cluster becomes the Master and the rest become Slaves. I guess some of you will have the question “but what if this master node fails?”. Well it is very simple, when the master node fails an election process is initiated and one of the slave nodes will be promoted to master and pick up where the master left off. On top of that, lets take the example of a Geo-Dispersed cluster, when the cluster is split in two sites due to a link failure each “partition” will get its own master. This allows for workloads to be restarted even in a geographically dispersed cluster when the network has failed….
What is this master responsible for? Well basically all the tasks that the primary nodes used to have like:
- restarting failed virtual machines
- exchanging state with vCenter
- monitor the state of slaves
As mentioned when a master fails a election process is initiated. The HA master election takes roughly 15 seconds. The election process is simple but robust. The host that is participating in the election with the greatest number of connected datastores will be elected master. If two or more hosts have the same number of datastores connected, the one with the highest Managed Object Id will be chosen. This however is done lexically; meaning that 99 beats 100 as 9 is larger than 1. That is a huge improvement compared to what is was like in 4.1 and prior isn’t it?
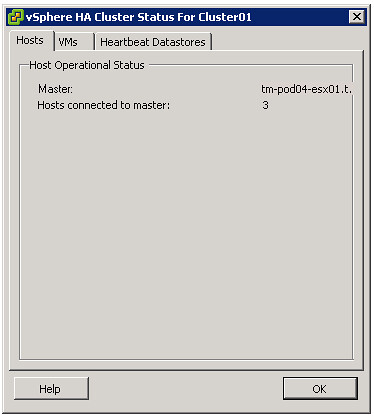
For those wondering which host won the election and became the master, go to the summary tab and click “Cluster Status”.
Isolated vs Partitioned
As this is a change in behavior I do want to briefly discuss the difference between an Isolation and a Partition. First of all, a host is considered to be either Isolated or Partitioned when it loses network access to a master but has not failed. To help explain the difference the states and the associated criteria below:
- Isolated
- Is not receiving heartbeats from the master
- Is not receiving any election traffic
- Cannot ping the isolation address
- Partitioned
- Is not receiving heartbeats from the master
- Is receiving election traffic
- (at some point a new master will be elected at which the state will be reported to vCenter)
In the case of an Isolation, a host is separated from the master and the virtual machines running on it might be restarted, depending on the selected isolation response and the availability of a master. It could occur that multiple hosts are fully isolated at the same time. When multiple hosts are isolated but can still communicate amongst each other over the management networks, it is called s a network partition. When a network partition exists, a master election process will be issued so that a host failure or network isolation within this partition will result in appropriate action on the impacted virtual machine(s).
** Disclaimer: This article contains references to the words master and/or slave. I recognize these as exclusionary words. The words are used in this article for consistency because it’s currently the words that appear in the software, in the UI, and in the log files. When the software is updated to remove the words, this article will be updated to be in alignment. **
Hi Duncan,
Let’s say, on cluster PROD01 network problem occurs and now we have two network partitions, election on new partition choose one of the node to be Primary. Cluster PROD01 has two primaries, if I understood correctly. What will happen with Master servers when network problem will be solved ?
New election ?
Artur
One of them will remain the master will the other becomes a slave. It will do this based on the MoID and the one with the highest ID will be the master.
I like the Storage heartbeats idea.
Will the new HA be used when you’re using vCenter 5 + ESXi 4.1? Or will you have to upgrade vCenter & ESXi before the new HA is used?
It will install the new agent, FDM, on the 4.1 host
How about on ESX4.0, the FDM will be installed?
Lifting the 5 primary nodes restriction seems really great.
What if the master node fails and with it the vCenter that was running on it? Or if one of the partitions loses connectivity to vCenter as well?
Do they still proceed with the master election and the following restart of VMs as usual?
Yes, master election occurs on a host level and does not require a connection with vcenter
Duncan,
Great information. Thanks for alot for it.
There is still one thing that is bothering me. Although network partitioned scenario, the election process does not require vcenter. But the newly elected master will still need the vcenter to configure the protection of VMs, right?
In that case, if the new partition and master cannot communicate with vcenter, can they still protect each other?
The third para needs a correction with respect to grammer.
“vSphere 5.0 has completed lifted these constraints” should be “vSphere 5.0 has completely lifted these constraints.”
Great article and I am impressed by the way FDM aka HA has been reworked by VMware. Awesome is the word.
when the isolated master was back online on HA cluster, does it become slave?
Yes it will
Does the new HA have any defined behavior for recovery from a complete datacenter power failure?
Same behavior as before as far as I am aware. As soon as the first host comes up it will become the master and it will try to restart VMs based on the information provided by the on-disk database.
Hi Duncan,
Great post, great change in v5 regarding the old HA model.
I do have 1 issue I’d like to clarify:
In 4.1 if you put 3-4 primary hosts (not all 5 of them) in maintenance mode at the same time, and then put some other 2-3 secondaries in maintenance mode if you took the secondaries out of maintenance mode before the primary hosts, the secondaries would not complete HA. it is as if they wanted the primary hosts to be ALL up and running.
You had to get a list of all primaries before doing the maintenance so you knew which ones to bring up before any secondary hosts.
Does this happen in 5.0? I mean in a rapidly changing host status situation (lots of hosts powering up and down) does FDM have any quirks like 4.1 HA did?
No HA/FDM has not. The concept used is completely different. For instance enabling HA on 32 nodes will take a minute or so to configure, the HA agent is pushed out in parallel instead of serial with 4.1 and prior.
Hi Duncan,
Great post! What is the impact on network IO since this model has changed? And how high is the impact on the master reacting to all the slaves?
Cheers,
Bouke
There are less heartbeats between the nodes so less network I/O then before. Also the datastore is used to exchange data as well.
Not sure I understand your second question…
Cool beans, this new H/A stuff is great. I still remember the dreaded APD issue – reboot all host in a cluster. This is definitely a milestone. Cannot wait to see what quirks or gotcha’s there are… too early to tell right now 😉
So is the 32 node cluster limit gone? What is the new maximum for the amount of hosts in a cluster with 5.0?
Limits have not been announced yet publicly so I cannot comment.
“When multiple hosts are isolated but can still communicate amongst each other over the management networks, it is called s a network partition.”
When these hosts are isolated, isn’t it because the management network is down? What networks are the hosts talking to each other over? Do you mean multiple hosts are isolated away from the master, but their management networks are fine?
“Do you mean multiple hosts are isolated away from the master, but their management networks are fine?”
Yes, it is possible, when for example some cable or switch problems. Especially when hosts in cluster are connected to different core switches in different DCs.
I also have some kind of question. If the master host is down the new elecstion become during next 15 seconds. So we have a small period(15s) when our cluster is without master and is UNPROTECTED. If during this period some another slave host go down, I think VMs from it will not be restarted…. Is it truly?
No, VMs will be restarted as soon as the new master is elected.
Duncan,
Excellent information. Thanks and keep up the good work! I have one question though, maybe I am just over analyzing it..
“On top of that, lets take the example of a Geo-Dispersed cluster, when the cluster is split in two sites due to a link failure each “partition” will get its own master. This allows for workloads to be restarted even in a geographically dispersed cluster when the network has failed…”
So if they the hosts in the two locations are partitioned but are still able to communicate to the vCenter, how will vCenter react to the fact that now the cluster is reporting two masters? Will vCenter try to rectify the issue or just play cool? If it will just lay low, will the cluster status now display two masters for the cluster?
Only 1 master will communicate with vCenter… So the data reflected by vCenter might not be 100% accurate.
In case of Geo-Dispersed cluster and Actif/Actif sotrage with bidirectional synchronous mirroring, a line failure will react with an Master election on remote site actual Master is on primary. HA restarts virtual machines and production up and running on both sites. In this case the storage is modified on both sites and production Data may change on both sites. This means in order to resynch the storage the data of one site has to be sratched(Data Loss).
Is it still possible to set the second site into isolation mode in order to avoid the same production server to be up and running on both sites at the same time?
Nothing has changed. Isolation Response responds to Network Heartbeats. The Datastore Heartbeat has been introduced to allow the master to determine what happened to the host, if it has failed or is isolated.