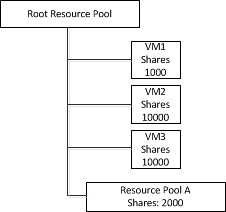
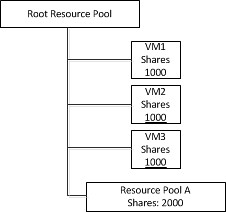
I was reviewing a document today and noticed something that I’ve seen a couple of times already. I already wrote about Active/Standby set ups for etherchannels a year ago but this is a slight different variant. Frank also wrote a more extensive article on it a while and I just want to re-stress this.
Scenario:
- Two NICs
- 1 Etherchannel of 2 links
- Both Management and VMkernel traffic on the same switch
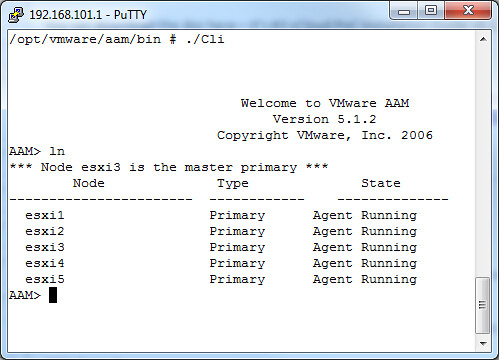
I created a simple diagram to depict this:
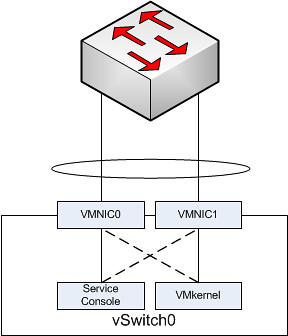
In the above scenario each “portgroup” is configured in an active/standby scenario. So let’s take the Service Console. It has VMNIC0 as active and VMNIC1 as standby. The physical switch however is configured with both NICs active in a single channel.
Based on the algorithm that etherchannels use either of the two VMNICs will accept inbound traffic. The Service Console however will only send traffic outbound via VMNIC0. Even worse, the Service Console isn’t actively listening to VMNIC1 for incoming traffic as it was placed in Standby mode. Standby mode means that it will only be used when VMNIC0 fails. In other words your physical switch will think it can use VMNIC1 for you Service Console but your Service Console will not see the traffic coming in on VMNIC1 as it is configured in Standby mode on the vSwitch. Or to quote from Frank’s article…
it will sit in a corner, lonely and depressed, wondering why nobody calls it anymore.