I’ve seen this a couple of times already and just had a very long phone call with a customer who created the following set up:
So basically the first two nics are active with load balancing set to IP-Hash and configured as an Etherchannel on the stacked Cisco 3750’s. The second pair are “standby”. Also with load balancing set to IP-Hash and configured as a second Etherchannel on the stacked Cisco 3750’s. A diagram probably makes more sense:
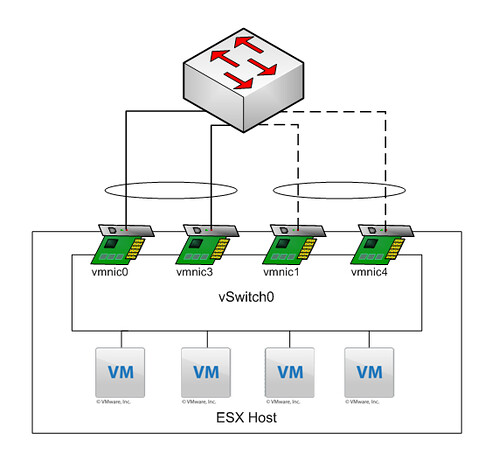
Explanation: All NICs belong to the same vSwitch. Etherchannel 01 consist of “vmnic0” and “vmnic3” and both are active. Etherchannel 02 consists of “vmnic1” and “vmnic4” and both are standby.
My customer created this to ensure a 2Gb link is always available. In other words if “vmnic3” fails “vmnic1” and “vmnic4” should take over as they are a “pair”. But is this really what happens when “vmnic3” fails?
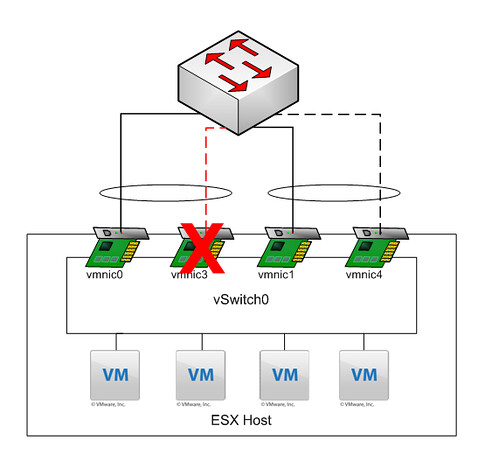
As you can clearly see, what they expected to happen did not happen. When “vmnic3” failed VMware ESX “promoted” the first standby NIC to active, which in this case belongs to a different Etherchannel. What happened next was not a pretty sight, mac-address table went completely nuts with “MACFLAPS” all over the place. I’m not a networking guy but I can tell you this introducing a loop when you configured portfast is not a smart idea. DON’T DO THIS AT HOME KIDS!
Ouch, doesn’t it make more sense to just have 4 way Etherchannel? Then you have 4Gb (kinda) available, and no problems when a NIC fails….?
Yet another reason why ESX needs to support LACP. LACP was designed to help solve this problem, it would have detected the other NICs and added them to the same etherchannel, and removed links that weren’t configured correctly on both sides.
And Nevyn, that’s correct, although I could see the rationale where the customer did two etherchannels to two separate switches, although with the 3750 as mentioned, you should Stackwise them together and use cross-stack etherchannel.
I wonder why people use etherchannels. Even in larger environments I’ve never seen a 1GB nic being the bottle neck. Is there really that often the need for 2GB?
Gabrie
I can’t tell you how many times I’ve had this same discussion. The first time I tried to do this, everything looked great on paper. Then we started testing: “What happened next was not a pretty sight…”
Duncan, we use this setup but with 4 active nics all in a team using IP Hash. Why wouldn’t this particular customer “use” the two nics instead of keeping them in standby?
I would said only use > 1GB nic for enhanced storage networking but not really for service console and vmkernel.
Good question Jonb157, no clue why they wanted to have it like this. They couldn’t give me a justification for it. I received the phone call because the local partner did not have a clue what was happening and happen to know me… and I knew the customer.
@ Gabrie – Why have a single active connection, when you you can have two active connections that keep working even if one connection fails? That’s why people use etherchannels.
If you are dedicating two ports to each vNIC for failover, you may as well use them.
Yes but a 4 NIC “Virtual Port ID” based load balancing “link” to the switches would also work fine. So why make it more complex than needed?
True, from a networking side, it’s nice to treat ESX as “just another switch” and cross switch Etherchannel it off in the same way you do any other switch…
I think we are agreed that having half your NICs sitting doing nothing isn’t too useful!
That is a good reason for MEC with stacked 3750’s and use three 1 Gb connections. More than likely only one port will fail and you can maintain your 2 Gb link requirement and save the 4th port all together.
For those wondering why you would etherchannel instead of load balance based on port ID, the reason is because when you do that, you get more effective load balancing, because it is balanced on source/dest IP address at the ESX host and can be balanced at the TCP conversation level at the switch.
In the example of a file server, a single file transfer from the server to the client can only go a maximum of 1Gbps (1 conversation) using both methods, but two transfers from two different clients to the file server will go at 1Gbps each, wheras it would still be 1Gbps shared with the virtual port ID method. This all assumes your disk storage can go that fast :).
Again, most workloads won’t utilize it, but shared SQL servers, File Servers, and Backup servers are the most common reasons to get improved performance using etherchannel over the standard virtual port ID, but virtual port ID is way simpler and doesn’t require expensive switches for proper redundancy, and what I generally recommend unless they either (a) already have something like 3750’s or (b) have a need to meet the requirement stated above but aren’t willing to go to 10Gb.
We have two Cisco 3750’s (not stacked). We configured this just the same way you explained in this article. I want to get rid of mac flapping, so what is the best way? Is there a way to keep the performance of the etherchannel and to use the 4 nics? It’s very easy when you’re using stackable switches, just add the 4 nics as active. But what do you need to do when you have two seperate switches, connected with an etherchannel? If I’m using an other teaming method, can I use two active (to switch1)/two passive nic (to switch2) config? Can I use the 4 NIC “Virtual Port ID” based load balancing method (two active (to switch1)/two passive nic (to switch2)) in this case and if I’m using this will it perform the same way?
What you want to achieve is not possible. You need to either have a 4 nic etherchannel to a single switch or create two seperate vswitches with each two nics bonded as an etherchannel. Another option would be, and this is the most redundant, flexible and simple solution: 4 nics, two attached to each 3750, NO etherchannels, Virtual PortID load balancing!
Hi, Duncan,
“4 nics, two attached to each 3750, NO etherchannels, Virtual PortID load balancing!”
In this case, can four nics be Active? Or two active and the other two standby?
Thanks~
If four nics can be set active, I need to trunk all 4 ports from two switches?
If only two can be set to active, how should I configure trunk on both switches for this four ports?
Sorry,I was confused about trunk and etherchanel.So forget that part. Let me just put it in a simple way, I would like to configure my esx :
-Four nics, two attached to each physical switch and no bonding should be configured on both physical switches.
-Load balancing policy set to “Routed based on virtual port id”
-Network Detection Failure set to “Beacon Probing”
-All nics set to “Active”
Will it work?
Yes it will, just make sure you enable Portfast on those ports and you are good to go!
Many thanks Duncan~
Great article and great blog!
Hi to all and congratulations for the site. I’ve this question: how is the better configuration for my environment? i’ve a blade c7000, 6 esx with 8 nic each one, 2 FC for SAN and 6 for network. In each esx the networking has this configuration: 1 vswitch for COS/VMKernel with 2 uplinks act/sta, 1 vswitch for VMs(portgroup 1 and 2) with 2 uplinks act/sta and another 1 vswitch for VMs(portgroup 3 and 4) with 2 uplinks act/sta. The active uplink are connect to a vConnect with a “network”(HP term)called “VM network 1” and the other stand-by nics are connect to another vConnect with other “network” called “VM network 2”. Each vConnect has 4 uplinks, one to a 3750’s LACP etherchannel trunk, and one to another 3750’s LACP ethcha trunk. The two 3750 are connect with a 2 port eth chan trunk. PVST is enable. Ports from cisco to vConnect are port-fast configured.
What’s the best configuration for me?
Thanks
I have one doubt,
Can configure 2 ether channels from single switch to 2 different switches which are connected to 2 different firewall?.
then is it perform load balancing?
can we consider it as a redundancy?
I don’t understand your question sorry…. it might be easier to open a topic on VMTN and provide me the link. (this way others can chip in as well)
You can’t use both IP Hash and a Virtual Connect module with all ports active – as somebody said, “it’s not a pretty sight”. Been there, done that, didn’t like it much.
See the HP document at http://h20195.www2.hp.com/v2/GetPDF.aspx/4AA2-9642ENW.pdf. It says you can use any load balancing algorithm you want *except* for IP Hash.
I guess that means you shouldn’t use IP-Hash at all with HP Virtualconnect.
how can i do my firewall asa 5520 failover
Not sure I understand how the question relates to this topic?