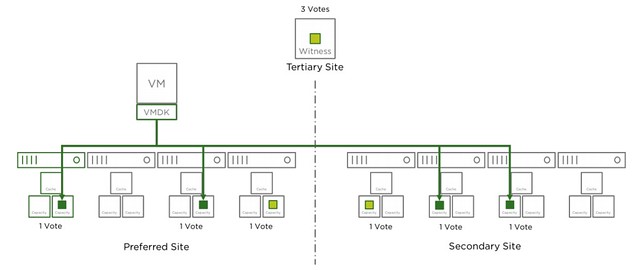
I have been having discussions with a customer who needs to disable DRS on a particular VM. I have written about disabling DRS for a host in the past, but not for a VM, well I probably have at some point but that was years ago. The goal here is to ensure that DRS won’t move a VM around but HA can still restart it. Of course you can create VM to Host rules, and you can create “must rules”. When you create must rules this could lead to an issue when the host on which the VM is running fails as HA will not restart it. Why? Well it is a “must rule”, which means that HA and DRS must comply to the rule specified. But there’s a solution, look at the screenshot below.
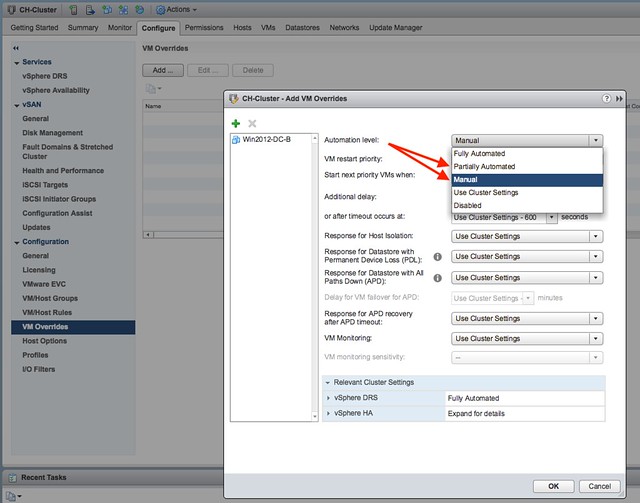
In the screenshot you see the “automation level” for the VM in the list, this is the DRS Automation level. (Yes the name will change in the H5 Client, making it more obvious what it is) You add VMs by clicking the green plus sign. Next you select the desired “automation mode” for those VMs and click okay. You can of course completely disable DRS for the VMs which should never be vMotioned by DRS, in this case during contention those “disabled VMs” are not considered at all. You can also set the automation mode to Manual or Partially Automated for those VMs as that gives you at least initial placement, but has as a downside that the VMs are considered for migration by DRS during contention. This could lead to a situation where DRS recommends that particular VM to be migrated, without you being able to migrate it. This in its turn could lead to VMs not getting the resources they require. So this is a choice you have to make, do I need initial placement or not?
If you prefer the VMs to stick to a certain host I would highly recommend to set VM/Host Rules for those VMs, use “should rules”, which define on which host the VM should run. Combined with the new Automation Level this will result in the VM being placed correctly, but not migrated by DRS when there’s contention. On top of that, it will allow HA to restart the VM anywhere in the cluster! Note that with “manual automation level” DRS will ask you if it is okay to place the VM on a certain host, with “partially automated” DRS will do the initial placement for you. In both cases balancing will not happen for those VMs automatically, but recommendations will be made, which you can ignore. (not use “safely”, as it may not be safe)