There we are, part 9 of the Startup News Flash. As mentioned last time, last week was “Storage Field Day” so typically a bit more news then normally this time of year. I would highly recommend to watch the videos. Especially the Coho video is very entertaining.
The original founders of Fusion IO (David Flynn and Rick White) just received 50 Million in funding for their new startup called Primary Data. I mentioned them briefly in Startup News Flash part 3 when they announced they started a new company and it seems that they have something on their hands! They haven’t revealed what they are working on, they are aiming to come out stealth around the second quarter of 2014. In the WSJ the following was mentioned in terms of the space these guys will be playing in: “The company is developing software–though it actually will come bundled on standard server hardware–that essentially connects all those pools of data together, offering what Flynn calls a “unified file directory namespace” visible to all servers in company computer rooms–as well as those “in the cloud” that might be operated by external service companies.” Indeed, something with storage / caching / software defined / scale-out…
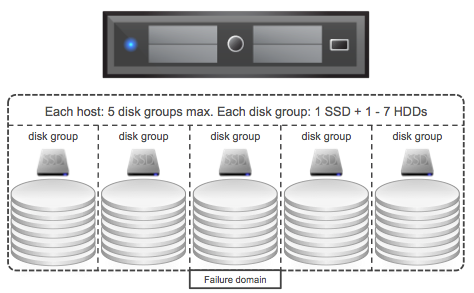
I guess scale-out hypervisor based storage solutions are hot… Maxta just officially announced their new product called MxSP. Some rumors had already been floating around but now the details are out their. Marcel v/d Berg did a nice article on them which I recommend reading if you like to get some more details. Basically Maxta created a Virtual Storage Appliance which pools all local storage and presents it as NFS to your hypervisor. Today VMware vSphere is fully supported and KVM / Hyper-V in a limited fashion. It offers functionality like VM-level snapshots and zero-copy clones, Thin provisioning, Inline deduplication and more. It looks like licensing is capacity based but no prices have been mentioned.
When first looking at Avere is was intrigued by their solution but somehow it didn’t really click. Primary focus was a caching layer in between your NFS storage and your hosts… But I wondered why I would want an extra box for that and not just use something host local. Last week Avere made announcement around a solution that allows you to pool local and cloud storage resources and present them via a common namespace and move data between these tiers. FlashCloud is what Avere calls it. Their paper describes it best, so a shameless copy of that: “FlashCloud software running on Avere FXT Edge filers addresses this challenge by storing cold data on cost-effective cloud storage at the core of the network and automatically and efficiently moving active data to the edge near the users.” I like the concept… If you are interested, check out their site here.
Far from a startup, but cool enough to be listed here… The release of the X-Brick aka XtremIO by EMC. The XtremIO solution is a brand new all-flash array which delivers screaming performance in a scale-out fashion. Although there are limitations from a scaling point of view today, it is expected that these will be lifted soon. One of the articles I enjoyed reading is this one by Jason Nash. What is most interesting about the product is the following, and I am going to quote Jason here as he is spot on: “There is no setup and tuning of XtremIO. No LUNs. No RAID Groups. No pools. No stripe sizes. No tiering. Nothing. You have a pool of very fast storage. How big do you want that LUN to be? That’s all you really need to do!”
Another round of funding for SimpliVity, Series C… 58 Million led by Kleiner Perkins Growth Fund and DFJ Growth with contributions by Meritech Capital Partners and Swisscom Ventures. I guess this GigaOM quote says it all: “CEO Doron Kempel, an EMC veteran, said the cash infusion will enable the company to execute on plans to triple its staff and boost sales growth five fold in 2014”.