I had a question this week on twitter, it was about the fact that DQLEN changes to values well below it was expected to be (30) in esxtop for a host. There was latency seen and experienced seen for VMs so the question was why is this happening and wouldn’t a lower DQLEN make things worse?
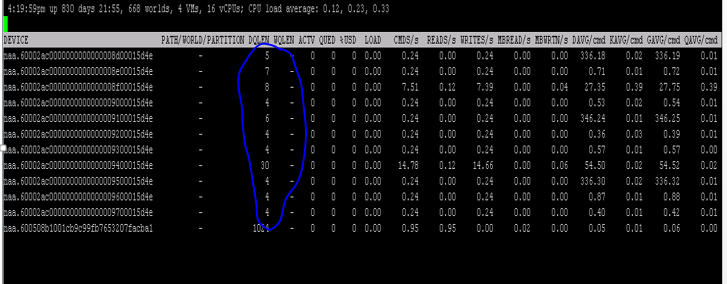
My first question: Do you have SIOC enabled? The answer was “yes”, and this is (most likely) what is causing the DQLEN changes. (What else could it be? Adaptive Queueing for instance.) When SIOC is enabled it will automatically change DQLEN when the configured latency threshold is exceeded based on the number of VMs per host and the number of shares. DQLEN will be changed to ensure a noisy neighbor VM is not claiming all I/O resources. I described how that works in this post in 2010 on Storage IO Fairness.
How do you solve this problem? Well, first of all, try to identify the source of the problems, this could be a single (or multiple) VMs, but it could also be that in general, the storage array is running at its peak constantly or backend services like replication is causing a slowdown. Typically it is a few (or one) VMs causing the load, try to find out which VMs are pushing the storage system and look for alternatives. Of course, that is easier said than done, as you may not have any expansion possibilities in the current solution. Offloading some of the I/O to a caching solution could also be an option (Infinio for instance), or replace the current solution with a more capable system is another one.