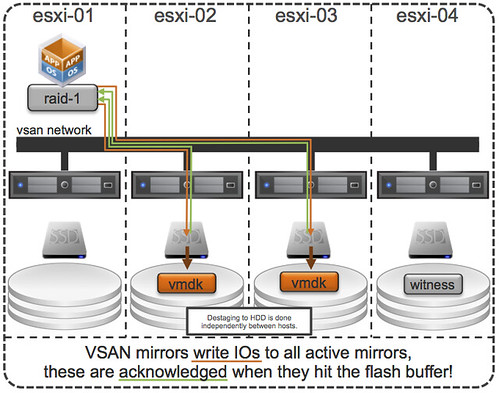
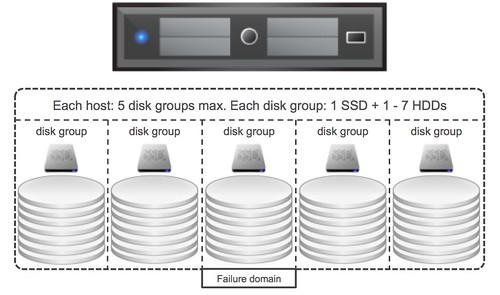
vSphere 6.0 was just announced and with it a new version of Virtual SAN. I don’t think it is needed to introduce Virtual SAN as I have written many many articles about it in the last 2 years. Personally I am very excited about this release as it adds some really cool functionality if you ask me, so what is new for Virtual SAN 6.0?
- Support for All-Flash configurations
- Fault Domains configuration
- Support for hardware encryption and checksum (See HCL)
- New on-disk format
- High performance snapshots / clones
- 32 snapshots per VM
- Scale
- 64 host cluster support
- 40K IOPS per host for hybrid configurations
- 90K IOPS per host for all-flash configurations
- 200 VMs per host
- 8000 VMs per Cluster
- up to 62TB VMDKs
- Default SPBM Policy
- Disk / Disk Group serviceability
- Support for direct attached storage systems to blade (See HCL)
- Virtual SAN Health Service plugin
 That is a nice long list indeed. Let my discuss some of these features a bit more in-depth. First of all “all-flash” configurations as that is a request that I have had many many times. In this new version of VSAN you can point out which devices should be used for caching and which will serve as a capacity tier. This means that you can use your enterprise grade flash device as a write cache (still a requirement) and then use your regular MLC devices as the capacity tier. Note that of course the devices will need to be on the HCL and that they will need to be capable of supporting 0.2 TBW per day (TB written) over a period of 5 years. For a drive that needs to be able to sustain 0.2 TBW per day, this means that over 5 years it needs to be capable of 365TB of writes. So far tests have shown that you should be able to hit ~90K IOPS per host, that is some serious horsepower in a big cluster indeed.
That is a nice long list indeed. Let my discuss some of these features a bit more in-depth. First of all “all-flash” configurations as that is a request that I have had many many times. In this new version of VSAN you can point out which devices should be used for caching and which will serve as a capacity tier. This means that you can use your enterprise grade flash device as a write cache (still a requirement) and then use your regular MLC devices as the capacity tier. Note that of course the devices will need to be on the HCL and that they will need to be capable of supporting 0.2 TBW per day (TB written) over a period of 5 years. For a drive that needs to be able to sustain 0.2 TBW per day, this means that over 5 years it needs to be capable of 365TB of writes. So far tests have shown that you should be able to hit ~90K IOPS per host, that is some serious horsepower in a big cluster indeed.
Fault Domains is also something that has come up on a regular basis and something I have advocated many times. I was pleased to see how fast the VSAN team could get it in to the product. To be clear, no this is not a stretched cluster solution… but I would see this as the first step, but that is my opinion and not VMware’s. This Fault Domain feature will allow you to specify fault domains per rack and then when you provision a new virtual machine VSAN will make sure that the components of the objects are placed in different fault domains.
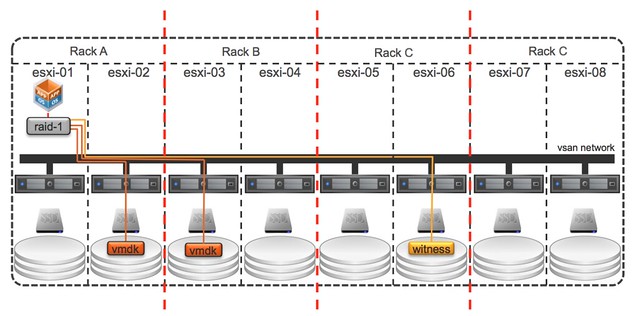
In this case when you do it per rack then even a full rack failure would not impact your virtual machine availability. Very cool indeed. The nice thing about the fault domain feature also is that it is very simple to configure. Literally a couple of clicks in the UI, but you can also use RVC or host profiles to configure it if you want to. Do note that you will need 6 hosts at a minimum for Fault Domains to make sense.
Then of course there is the scalability. Not just the 64 host cluster support but also the 200 VMs per host is a great improvement. Of course there is also the improvements around snapshot and cloning which can be attributed to the new on-disk format and the different snapshotting mechanism that is being used, less then 2% performance impact when going up to 32 levels deep is what we have been waiting for. Fair to say that this is where the acquisition of Virsto is coming in to play, and I think we can expect to see more. Also, the components number has gone up. The max number of components used to be 3000 and is now increased to 9000.
Then there is the support for blade systems with direct attached storage systems… this is very welcome, I had many customers asking for this. Note that as always the HCL is leading, so make sure to check the HCL before you decide to purchase equipment to implement VSAN in a blade environment. Same applies to hardware encryption and checksums, it is fully supported but make sure your components are listed with support for this functionality on the HCL! As far as I know the initial release will have 2 supported systems on there, one IBM system and I believe the Dell FX platform.
All of the operational improvements that were introduced around disk serviceability and being able to tag a device as “local / remote / SSD” are the direct result of feedback from customers and passionate VSAN evangelists internally at VMware. Also for instance pro-active rebalancing is now possible through RVC. If you add a host or remove a host and want to even out the nodes from a capacity point of view then a simple RVC command will allow you to do this. But also for instance the “resync” details can now be found in the UI, something I am very happy about as that will help people during PoCs not to run in to the scenario where they introduce new failures while VSAN is recovering from previous failures.
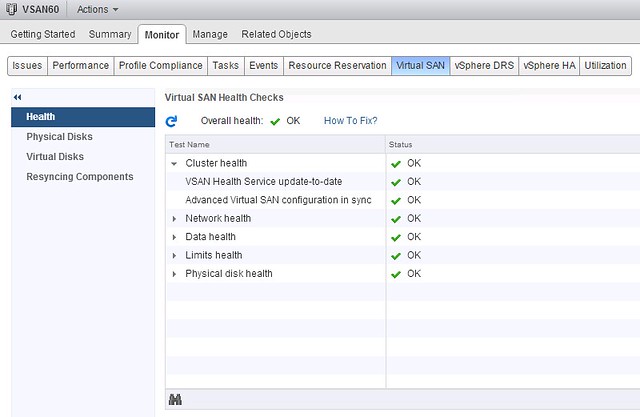
Last one I want to mention is the Virtual SAN Health Service plugin. This is a separately developed Web Client plugin that will provide in-depth information about Virtual SAN. I gave it a try a couple of weeks ago and now have it running in my environment, impressed with what is in there and great to see this type of detail straight in the UI. I expect that we will see various iterations in the upcoming year.