After attending Irfan Ahmad’s session on Storage IO Control at VMworld I had the pleasure to sit down with Irfan and discuss SIOC. Irfan was so kind to review my SIOC articles(1, 2) and we discussed a couple of other things as well. The discussion and the Storage IO Control session contained some real gems and before my brain resets itself I wanted to have these documented.
Storage IO Control Best Practices:
- Enable Storage IO Control on all datastores
- Avoid external access for SIOC enabled datastores
- To avoid any interference SIOC will stop throttling, more info here.
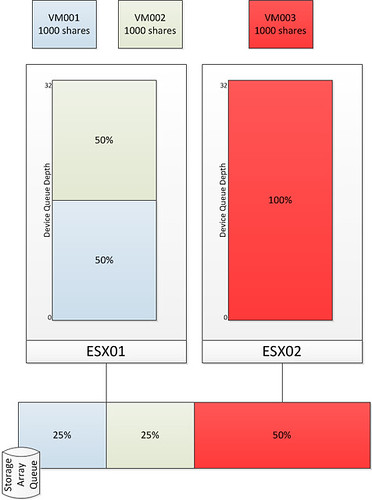
- When multiple datastores share the same set of spindles ensure all have SIOC enabled with comparable settings and all have sioc enabled.
- Change latency threshold based on used storage media type:
- For FC storage the recommended latency threshold is 20 – 30 MS
- For SAS storage the recommended latency threshold is 20 – 30 MS
- For SATA storage the recommended latency threshold is 30 – 50 MS
- For SSD storage the recommended latency threshold is 15 – 20 MS
- Define a limit per VM for IOPS to avoid a single VM flooding the array
- For instance limit the amount of IOPS per VM to a 1000