I was preparing a post on Storage I/O Control (SIOC) when I noticed this article by Alex Bakman. Alex managed to capture the essence of SIOC in just two sentences.
Without setting the shares you can simply enable Storage I/O controls on each datastore. This will prevent any one VM from monopolizing the datatore by leveling out all requests for I/O that the datastore receives.
This is exactly the reason why I would recommend anyone who has a large environment, and even more specifically in cloud environments, to enable SIOC. Especially in very large environments where compute, storage and network resources are designed to accommodate the highest common factor it is important to ensure that all entities can claim their fair share of resource and in this case SIOC will do just that.
Now the question is how does this actually work? I already wrote a short article on it a while back but I guess it can’t hurt to reiterate thing and to expand a bit.
First a bunch of facts I wanted to make sure were documented:
- SIOC is disabled by default
- SIOC needs to be enabled on a per Datastore level
- SIOC only engages when a specific level of latency has been reached
- SIOC has a default latency threshold of 30MS
- SIOC uses an average latency across hosts
- SIOC uses disk shares to assign I/O queue slots
- SIOC does not use vCenter, except for enabling the feature
When SIOC is enabled disk shares are used to give each VM its fair share of resources in times of contention. Contention in this case is measured in latency. As stated above when latency is equal or higher than 30MS, and the statistics around this are computed every 4 seconds, the “datastore-wide disk scheduler” will determine which action to take to reduce the overall / average latency and increase fairness. I guess the best way to explain what happens is by using an example.
As stated earlier, I want to keep this post fairly simple and I am using the example of an environment where every VM will have the same amount of shared. I have also limited the amount of VMs and hosts in the diagrams. Those of you who attended VMworld session TA8233 (Ajay and Chethan) will recognize these diagrams, I recreated and slightly modified them.
The first diagram shows three virtual machines. VM001 and VM002 are hosted on ESX01 and VM003 is hosted on ESX02. Each VM has disk shares set to a value of 1000. As Storage I/O Control is disabled there is no mechanism to regulate the I/O on a datastore level. As shown in the bottom by the Storage Array Queue in this case VM003 ends up getting more resources than VM001 and VM002 while all of them from a shares perspective were entitled to the exact same amount of resources. Please note that both Device Queue Depth’s are 32, which is the key to Storage I/O Control but I will explain that after the next diagram.
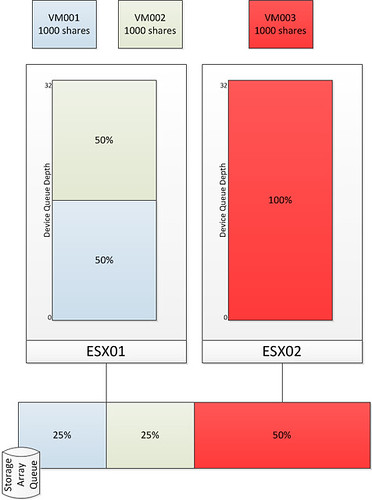
As stated without SIOC there is nothing that regulates the I/O on a datastore level. The next diagram shows the same scenario but with SIOC enabled.

After SIOC has been enabled it will start monitoring the datastore. If the specified latency threshold has been reached (Default: Average I/O Latency of 30MS) for the datastore SIOC will be triggered to take action and to resolve this possible imbalance. SIOC will then limit the amount of I/Os a host can issue. It does this by throttling the host device queue which is shown in the diagram and labeled as “Device Queue Depth”. As can be seen the queue depth of ESX02 is decreased to 16. Note that SIOC will not go below a device queue depth of 4.
Before it will limit the host it will of course need to know what to limit it to. The “datastore-wide disk scheduler” will sum up the disk shares for each of the VMDKs. In the case of ESX01 that is 2000 and in the case of ESX02 it is 1000. Next the “datastore-wide disk scheduler” will calculate the I/O slot entitlement based on the the host level shares and it will throttle the queue. Now I can hear you think what about the VM will it be throttled at all? Well the VM is controlled by the Host Local Scheduler (also sometimes referred to as SFQ), and resources on a per VM level will be divided by the the Host Local Scheduler based on the VM level shares.
I guess to conclude all there is left to say is: Enable SIOC and benefit from its fairness mechanism…. You can’t afford a single VM flooding your array. SIOC is the foundation of your (virtual) storage architecture, use it!
ref:
PARDA whitepaper
storage i/o control whitepaper
vmworld storage drs session
vmworld storage i/o control session
Why is SIOC not enabled by default?
Hi Duncan,
Do you need a certain license level to enable SIOC? If vCenter is only needed when enabling the feature, who will keep track of latencies when a datastore is shared between multiple hosts?
Thank you,
Dan
Dan: All of the hosts will be experiencing the same latency (unless the problem is local kernel or queue based latency) which means all hosts will enact SIOC.
If the latency is NOT being seen on a particular host, well, then thats no big deal and SIOC does not need to engage on that host.
A shared datastore will exhibit the same latency on all hosts. If it doesn’t it likely means very little IO is being done from that other host and therefore SIOC does not need to engage – but it would engage as soon as it detected the latency.
So keeping track of it through vCenter for example to coordinate all hosts is not necessary. Think of it like throttling the port in a virtual distributed switch. You don’t need to make the change on each host, the vds sends that change with the VM as the VM moves hosts. You could enable SIOC on a host by host basis but if you didn’t, the offending VM might be on a host that doesn’t have SIOC enabled and therefore that VM will never get throttled.
To further clarify that last paragraph. A change on the vds, while controlled through vCenter, is universal on all hosts in the vds so the change only needs to happen in one location but each host will react as it needs to. But if you did port limiting on a standard vSwitch you would have to make the change on each host otherwise the throttling would not carry over if the VM vmotion’d.
SIOC, while not needing vCenter to manage it, is the same way.
Seems to me that the VMs most likely to do a lot of storage IO are the ones most likely to end up in their own datastore, so until I can group datastores together and set shares based on the groups I don’t see a lot of use for this feature. Even better would be a plugin from the SAN vendors that could automatically manage these groups based on which datastores are sharing the same disks.
@lieve: Good question, I guess it isn’t enabled by default as it is a new concept. I will ask the developer though.
@Brad: well isn’t it usually the VM which you don’t expect to cause any issues that goes nuts? Those are the type of VMs that end up on a single datastore with 10/20 others, why not ensure you won’t run into any issues by simply enabling this feature? Especially in larger environments I do see a valid reason to enable this, or even better in any environment where you have multiple VMs on a single datastore which is shared across multiple host you can and will benefit from SIOC at some point.
@Duncan: I think the feature has some good uses as it is, I just think that they are limited by the current implementation. It could even be a bad thing in the wrong environment. For example, what would happen if VM003 were moved to a different datastore on the same disks as VM001 and VM002 and then VM003 went crazy on the IO? It looks like no throttling would happen to VM003, but VM001 and VM002 would be forced to share whatever IO they could “win” from the array. Adding more VMs to the first datastore doesn’t do anything to VM003, but VM001 and VM002 continue to to get slower since they have to split their shares among more VMs. Without SIOC each of the VMs would have equal opportunity to fight for IO and they would have all slowed down together.
@Brad: I seriously don’t understand what you are trying to get across.
1) Shares only come into play when there is contention
2) It is on a per datastore level across hosts
3) instead of 1 VM on a different Host being able to slow down VMs on another host, you now have the ability to regulate that.
4) throttling happens on the Host not on the array.
But I have trouble digesting your example to be honest.
I think it would be of great value in vCD environment where there is no way to manage the shares on individual VMs and the VM creation would be dynamic.
1. Where does datastore-wide disk scheduler runs from?
2. Can anyway control the I/O contention in vCD VM environment (say one VM running high I/O impacting another VM running on same host/datastore)
I can’t enable SIOC with an Enterprise licence – “License not available to perform the operation”. Is it Enterprise Plus only?
This doesn’t appear to work in NFS? (not supported according to my 4.1 cluster)
Any plans on having this level of granularity for this in the future that you’re aware of? NFS has so many awesome features, but in some ways still feels like the redheaded stepchild of vmware supported storage. Especially w/ the upcoming inability to have a nfstop utility due to being all esxi, i’m concerned about locating bottlenecks.
thx.
It doesn’t work with NFS indeed.
Its Enterprise Plus only 🙁
Another careful prod by VMware to buy the top tier product.
Hi Duncan, great article 🙂
I’m struggling to get my head around what the impact will be upon ourselves, as we have been instructed by Hitachi (we use AMS2000 arrays) to set the queue depth to 8.
If the SIOC will not go below a queue depth of 4, doesn’t that seriously hamper SIOC’s ability to fairly share the resources?
I’m not sure what the effect will be, and haven’t tested it to confirm either way, but I was wondering if you’d be able to take a stab as to the likely observed effect?
FYI – This is for a future product I’m working on, using VMware in a Multi-Tenant environment, for shared hosting. We’re looking to do what we can to “level the playing field” so SIOC is hugely interesting!!
@Brad: How can you have single disk to be allocated to two different datastore?
Great article to explain SIOC, but please update it –
1) SIOC is not supported for NFS (esxi 5.x)
2) 30ms Normalized latency can change automatically based on type of backend disks.. i.e. 15ms for SSD I thinks.. SIOC has become smarter in 5.1
I meant SIOC is NOW* supported for NFS
If I can find the time I will…
Using ESXi 5.1. I have 2 VMs on the same host
vm1 -Installed on NFS
vm2 – installed locally. but has a second disk from the NFS
SIOC enabled on NFS. Default settings on both Vms.
My question:
Will SIOC come into action when vm2 access its second disk?
( I had an issue with VDR when backing up vms installed on the NFS. Because of the heavy IO from the VDR to NFS , the vms couldn’t access the NFS and stopped responding)
J James,
SIOC uses the number of shares assigned to the virtual disk to determine priority only during times of contention. If there is no contention then SIOC does not come into play. However if there is contention on the NFS datastore where the second disk of vm2 resides, then SIOC would use the number of shares to determine scheduling priority for that second disk not effecting the first disk. SIOC is simply the system that allows you to control disk shares at the datastore level. Think of SIOC the same way you would configure Resource Pools for CPU and Mem, however it is for storage.
SIOC is just one of the pieces to standardize resource scheduling across a virtual environment. The 4 system components that are abstracted and then aggregated with VMware are CPU, Mem, Storage and Network. Resource Pools control CPU and Mem, vDS’s control Network traffic, SIOC controls storage. These resource scheduling features of VMware can be globally configured to standardize the configurations.
Hope this helps put it into perspective and what individual resource scheduling tools can be used.
Great article and discussion. I think Brad too made a good point. What is true at one level in a virtualised environment, may not necessarily be true at another. A LUN may be presenting an entire RAID group or a portion of it, in which case multiple LUNs created within the same RAID group will share disks. Here is a nice visual representation of shared disks
http://www.fujitsu.com/global/services/computing/storage/eternus/products/diskstorage/feature/strsys-d10.html
Great article, thanks 🙂
I just wanted to add that the shares are default to 1000 per disk, not per VM.