I was reading this blog post on VSAN VDI Benchmarking today on Vroom, the VMware Performance blog. You see a lot of people doing synthetic tests (max iops with sequential reads) on all sorts of storage devices, but lately more and more vendors are doing these more “real world performance tests”. While reading this article about VDI benchmarking, and I suggest you check out all parts (part 1, part 2, part 3), there was one thing that stood out to me and that was the comparison between VSAN and an All Flash Array.
The following quotes show the strength of VSAN if you ask me:
we see that VSAN can consolidate 677 heavy users (VDImark) for 7-node and 767 heavy users for 8-node cluster. When compared to the all flash array, we don’t see more than 5% difference in the user consolidation.
Believe me when I say that 5% is not a lot. If you are actively looking at various solutions, I would highly recommend to include the “overhead costs” to your criteria list as depending on the solution chosen this could make a substantial difference. I have seen other solutions requiring a lot more resources. But what about response time, cause that is where the typical All Flash Array shines… ultra low latency, how about VSAN?
Similar to the user consolidation, the response time of Group-A operations in VSAN is similar to what we saw with the all flash array.
Both very interesting results if you ask me. Especially the < 5% in user consolidation is what stood out to me the most! Once again, for more details on these tests read the VDI Benchmarking blog part 1, part 2, part 3!
Beta Refresh
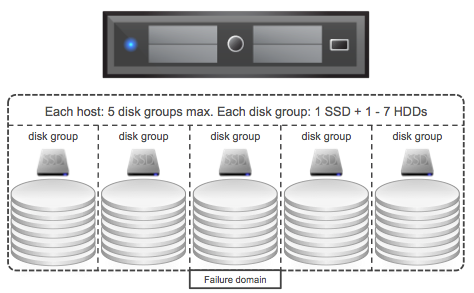
For those who are testing VSAN, there is a BETA refresh available as of today. This release has a fix for the AHCI driver issue… and it increases the disk group limit from 6 to 7. From a disk group perspective this will come in handy as many servers have 8, 16 or 24 disk slots allowing you to do 7HHDs + 1 SSD per group. Also some additional RVC commands have been added in the storage policy space, I am sure they will come in handy!
Nice side affect of the number of HDDs going up is increase in max capacity:
(8 hosts * (5 diskgroups * 7 HDDs)) * Size of HDD = Total capacity
With 2 TB disks this would result in:
(8 * (5 * 7)) * 2TB = 560TB
Now keep on testing with VSAN and don’t forget to report feedback through the community forums or your VMware rep.