It is that time of the year again, a new vSphere release announcement! (For those interested in what’s new for vSAN make sure to read my other post.) vSphere 6.7, what’s in a name / release? Well a bunch of stuff, and I am not going to address all of the new functionality as the list would simply be too long. So this list features what I think is worth mentioning and discussing.
- vSphere Client (HTML-5) is about 95% feature complete
- Improved vCenter Appliance monitoring
- Improved vCenter Backup Management
- ESXi Single Reboot Upgrades
- ESXi Quick Boot
- 4K Native Drive Support
- Max Virtual Disks increase from 60 to 256
- Max ESXi number of Devices from 512 to 1024
- Max ESXi paths to Devices from 2048 to 4096
- Support for RDMA
- vSphere Persistent Memory
- DRS initial placement improvements
Note that there’s a whole bunch of stuff missing from this list, for instance there were many security enhancements, but I don’t see the point of me pretending to be an expert on that topic, while I know some of the top experts will have a blog out soon.
Not sure what I should tell about the vSphere Client (h5) at this point. Everyone has been waiting for this, and everyone has been waiting for it to reach ~90/95% feature complete. And we are there. I have been using it extensively for the past 12 months and I am very happy with how it turned out. I think the majority of you will be very very happy with what you will see and with the overall experience. It just feels fast(er) and seems more intuitive.
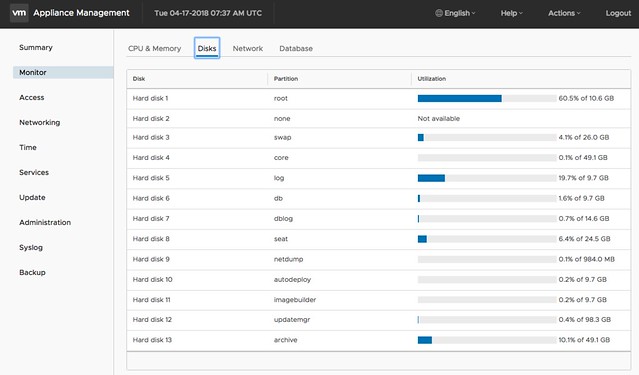
When it comes to management and monitoring of the vCenter Appliance (https://ip of vcenter:5480) there are a whole bunch of improvements. For me personally the changes in the monitoring tab are very useful and also the services tab is useful. Now you can immediately see when a particular disk is running out of space, as shown in the screenshot below. And you can for instance restart a particular service in the “Services” tab.
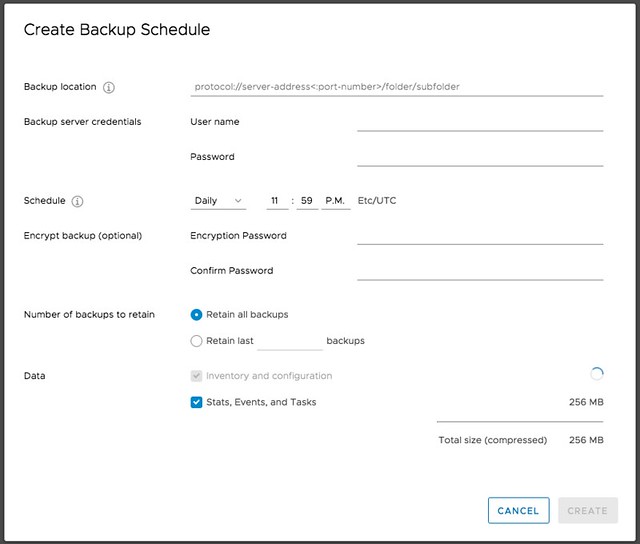
Next is vCenter Backup Management, a lot of people have been asking for this. We introduced Backup and Recovery of the appliance a while ago, very useful, but unfortunately it didn’t provide a scheduling mechanism. Sure you could create a script that would do this for you on a regular cadence, but not everyone wants to bother with that. Now in the Appliance Management UI you can simply create a schedule for backup. This is one of those small enhancements, which to me is a big deal! I’m sure that Emad or Adam will have a blog out soon on the topic of vCenter enhancements, so make sure to follow their blogs.
Another big deal is the fact that we shaved off a reboot for major upgrades. As of 6.7 you now only have 1 reboot with ESXi. Again, a tiny thing going from 2 back to 1, but when you have servers taking 10-15 minutes to go through the reboot process and you have dozens to of servers to reboot it makes Single Reboot ESXi Upgrades a big thing. For those on 6.5 right now, you will be able to enjoy the single reboot experience when upgrading to 6.7!
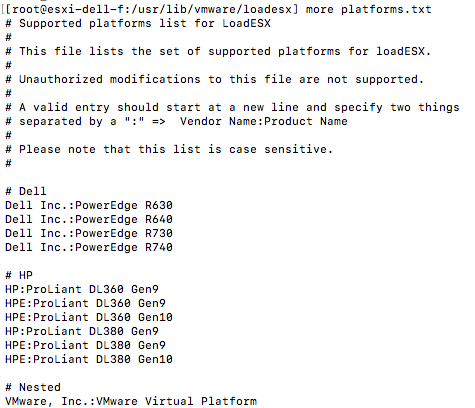
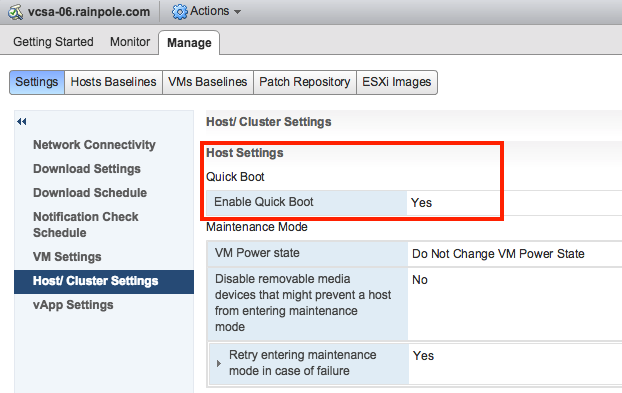
One feature I have personally been waiting for is ESXi Quick Boot. I saw a demo of this last year at our internal R&D conference at VMware and I was impressed. I don’t think many people at that stage saw the importance of the feature, but I am glad it made it in to the release. So what is it? Well basically it is a way to restart the hypervisor without going through the physical hardware reboot process. This means that you are now removing that last reboot, of course this only applies when your used server hardware supports it. Note that with the first release only a limited set of servers will support it, nevertheless this is a big thing. Not just for reboots, but also for upgrades / updates. A second ESXi memory image can be created and updated and when rebooting simply switched over to the latest and greatest instead of doing a full reboot. It will save, again, a lot time. I looked at a pre-GA build and noticed the following platforms are supported, this should be a good indication:
Of course you can also see if the host is supported in the vSphere Client, I found it in the Web Client but not in the H5 Client, maybe I am overlooking it, that could of course be the case.
Then up next are a bunch of core storage enhancements. First 4K Native Drive Support, very useful for those who want to use the large capacity devices. Not much else to say about it other than that it will also be supported by vSAN. I do hope that those using it for vSAN do take the potential performance impact in to account. (High capacity, Low IOPS >> low iops per GB!) Up next is the increase of a bunch of “max values“. Number of virtual disks going from 60 to 256 virtual disks for PVSCSI. And on top of that the number of Paths and Devices is also going up. Number of devices doubled from 512 to 1024 per host, and so has the number of paths as it is going from 2048 to 4096. Some of our largest customers will definitely appreciate that!
Then there’s also the support for RDMA, which is great for applications requiring extremely low latency and very high bandwidth! Note that when RDMA is used most of the ESXi Network stack is skipped, and when used in pass-through mode this also means that vMotion is not available. So that will only be useful for scale-out applications which have their own load balancing and high availability functionality. For those who can tolerate a bit more latency a paravirtualized RDMA adaptor will be available, you will need HW version 13 for this though.
vSphere Persistent Memory is something that I was definitely excited about. Although there aren’t too many supported server configurations, or even persistent memory solutions, it is something that introduces new possibilities. Why? Well this will provide you performance much higher than SSD at a cost which is lower than DRAM. Think less than 1 microsecond of latency. Where nanoseconds is for DRAM and Flash typically is low milliseconds under load. I have mentioned this in a couple of my sessions so far, NVDIMM will be big, which is the name commonly used for Persistent Memory. For those planning on buying persistent memory, do note that your operating system also needs to understand how to use it. There is a Virtual NVDIMM device in vSphere 6.7 and if the Guest OS has support for it then it will be able to use this byte addressable device. I believe a more extensive blog about vSphere Persistent Memory and some of the constraints will appear on the Virtual Blocks blog soon, so keep an eye on that as well. Cormac already has his fav new 6.7 features up on his blog, make sure to read that as well.
And last but not least, there was a significant improvement done in the initial placement process for DRS. Some of this logic was already included in 6.5, but only worked when HA was disabled. As of 6.7 it is also available when HA is enabled, making it much more likely that you will be able to benefit from the 3x decrease in time that it takes for the initial placement process to complete. A big big enhancements in the DRS space. I am sure though that Frank Denneman will have more to say about this.