As most of you have seen, vSAN 6.7 just released together with vSphere 6.7. As such I figured it was time to write a “what’s new” article. There are a whole bunch of cool enhancements and new features, so let’s create a list of the new features first, and then look at them individually in more detail.
- HTML-5 User Interface support
- Native vRealize Operations dashboards in the HTML-5 client
- Support for Microsoft WSFC using vSAN iSCSI
- Fast Network Failovers
- Optimization: Adaptive Resync
- Optimization: Witness Traffic Separation for Stretched Clusters
- Optimization: Preferred Site Override for Stretched Clusters
- Optimization: Efficient Resync for Stretched Clusters
- New Health Checks
- Optimization: Enhanced Diagnostic Partition
- Optimization: Efficient Decomissioning
- Optimization: Efficient and consistent storage policies
- 4K Native Device Support
- FIPS 140-2 Level 1 validation
Yes, that is a relatively long list indeed. Lets take a look at each of the features. First of all, HTML-5 support. I think this is something that everyone has been waiting for. The Web Client was not the most loved user interface that VMware produced, and hopefully the HTML-5 interface will be viewed as a huge step forward. I have played with it extensively over the past 6 months and I must say that it is very snappy. I like how we not just ported over all functionality, but also looked if workflows could be improved and if presented information/data made sense in each and every screen. This also however does mean that new functionality from now on will only be available in the HTML-5 client, so use this going forward. Unless of course the functionality you are trying to access isn’t available yet, but most of it should be! For those who haven’t seen it yet, here’s a couple of screenshots… ain’t it pretty? 😉
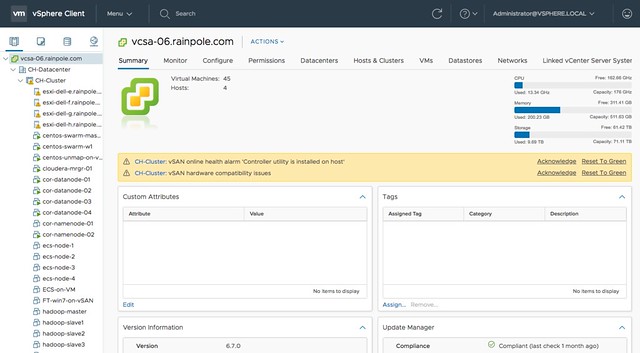
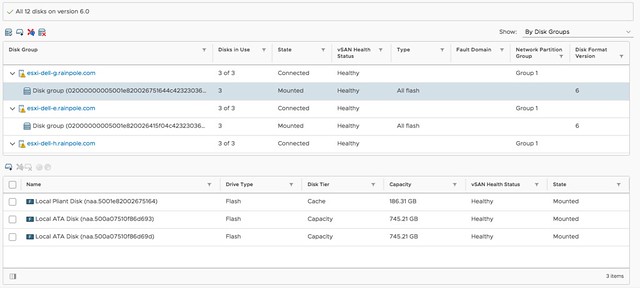
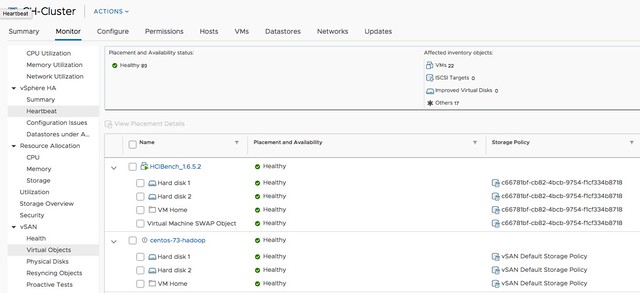
For those who didn’t notice, but in the above screenshot you actually can see the swap file, and the policy associated with the swap file, which is a nice improvement!
The next feature is native vROps dashboards for vSAN in the H5 client. I found this very useful in particular. I don’t like context switching and this feature allows me to see all of the data I need to do my job in a single user interface. No need to switch to the VROps UI, but instead vSphere and vSAN dashboards are now made available in the H5 client. Note that it needs the VROps Client Plugin for the vCenter H5 UI to be installed, but that is fairly straight forward.
Next up is support for Microsoft Windows Server Failover Clustering for the vSAN iSCSI service. This is very useful for those running a Microsoft cluster. Create and iSCSI Target and expose it to the WSFC virtual machines. (Normally people used RDMs for this.) Of course this is also supported with physical machines. Such a small enhancement, but for customers using Microsoft clustering a big thing, as it now allows you to run those clusters on vSAN without any issues.
Next are a whole bunch of enhancements that have been added based on customer feedback of the past 6-12 months. Fast Network Failovers was one of those. Majority of our customers have a single vmkernel interface with multiple NICs associated with them, some of our customers have a setup where they create two vmkernel interfaces on different subnets, each with a single NIC. What that last group of customers noticed is that in the previous release we waited 90 seconds before failing over to the other vmkernel interface (tcp time out) when a network/interface had failed. In the 6.7 release we actually introduce a mechanism that allows us to failover fast, literally within seconds. So a big improvement for customers who have this kind of network configuration (which is very similar to the traditional A/B Storage Fabric design).
Adaptive Resync is an optimization to the current resync function that is part of vSAN. If a failure has occurred (host, disk, flash failure) then data will need to be resynced to ensure that the impacted objects (VMs, disks etc) are brought in to compliance again with the configured policy. Over the past 12 months the engineering team has worked hard to optimize the resync mechanism as much as possible. In vSAN 6.6.1 a big jump was already made by taking VM latency in to account when it came to resync bandwidth allocation, and this has been further enhanced in 6.7. In 6.7 vSAN can calculate the total available bandwidth, and ensures Quality Of Service for the guest VMs prevails by allocating those VMs 80% of the available bandwidth and limiting the resync traffic to 20%. Of course, this only applies when congestion is detected. Expect more enhancements in this space in the future.
A couple of release ago we introduced Witness Traffic Separation for 2 Node configurations, and in 6.7 we introduce the support for this feature for Stretched Clusters as well. This is something many Stretched vSAN customers have asked for. It can be configured through the CLI only at this point (esxcli) but that shouldn’t be a huge problem. As mentioned previously, what you end up doing is tagging a vmknic for “witness traffic” only. Pretty straight forward, but very useful:
esxcli vsan network ip set -i vmk<X> -T=witness
Another enhancement for stretched clusters is Preferred Site Override. It is a small enhancements, but in the past when the preferred site failed and returned for duty but would only be connected to the witness, it could happen that the witness would bind itself directly to the preferred site. This by itself would result in VMs becoming unavailable. This Preferred Site Override functionality would prevent this from happening. It will ensure that VMs (and all data) remains available in the secondary site. I guess one could also argue that this is not an enhancement, but much more a bug fix. And then there is the Efficient Resync for Stretched Clusters feature. This is getting a bit too much in to the weeds, but essentially it is a smarter way of bringing components up to the same level within a site after the network between locations has failed. As you can imagine 1 location is allowed to progress, which means that the other location needs to catch up when the network returns. With this enhancement we limit the bandwidth / resync traffic.
And as with every new release, the 6.7 release of course also has a whole new set of Health Checks. I think the Health Check has quickly become the favorite feature of all vSAN Admins, and for a good reason. It makes life much easier if you ask me. In the 6.7 release for instance we will validate consistency in terms of host settings and if an inconsistency is found report this. We also, when downloading the HCL details, will only download the differences between the current and previous version. (Where in the past we would simply pull the full json file.) There are many other small improvements around performance etc. Just give it a spin and you will see.
Something that my team has been pushing hard for (thanks Paudie) is the Enhanced Diagnostic Partition. As most of you know when you install / run ESXi there’s a diagnostic partition. This diagnostic partition unfortunately was a fixed size, with the current release when upgrading (or installing green field) ESXi will automatically resize the diagnostic partition. This is especially useful for large memory host configurations, actually useful for vSAN in general. No longer do you need to run a script to resize the partition, it will happen automatically for you!
Another optimization that was released in vSAN 6.7 is called “Efficient Decomissioning“. And this is all about being smarter in terms of consolidating replicas across hosts/fault domains to free up a host/fault domain to allow for maintenance mode to occur. This means that if a component is striped, for other reasons then policy, they may be consolidated. And the last optimization is what they refer to as Efficient and consistent storage policies. I am not sure I understand the name, as this is all about the swap object. Per vSAN 6.7 it will be thin provisioned by default (instead of 100% reserved), and also the swap object will now inherit the policy assigned to the VM. So if you have FTT=2 assigned to the VM, then you will have not two but three components for the swap object, still thin provisioned so it shouldn’t really change the consumed space in most cases.
Then there are the two last items on the list: 4K Native Device Support and FIPS 140-2 Level 1 validation. I think those speak for itself. 4K Native Device Support has been asked for by many customers, but we had to wait for vSphere to support it. vSphere supports it as of 6.7, so that means vSAN will also support it Day 0. The VMware VMkernel Cryptographic Module v1.0 has achieved FIPS 140-2, vSAN leverages the same module for vSAN Encryption. Nice collaboration by the teams, which is now showing the big benefit.
Anyway, there’s more work to do today, back to my desk and release the next article. Oh, and if you haven’t seen it yet, Virtual Blocks also has a blog and there’s a nice podcast on the topic of 6.7 as well.
Nice resumen. It makes me to go deep in a lab. Thanks
Hi Duncan!
I have an question about the new fast network failovers, when you say “literally within seconds” how many seconds is need to do that? I know, the most obvious answer here is depend but how many seconds more or less?
Thanks!
vSAN iSCSI Target Configured GOS level , Configured Disk not showing in Fail-over Cluster Quorum Configuration ( vSPHere and vSAN 6.7 , WINdows 2012 R2 with Fail Over Clustering )
Is this supported in vSAN 6.7 ?
Hi Duncan,
Just checking with you. In the efficient resync you mention “With this enhancement we limit the bandwidth / resync traffic.”. This looks more like the adaptive resync feature.
In storagehub the efficient resync feature is described as a resync of only one component to a proxy host in the remote site which in turn rebuilds it on its peers locally.