Cormac Hogan and I have been working late nights and weekends over the past months to update our vSAN book material. Thanks Cormac, it was once again a pleasure working with you on this project! As you may know, we released two versions of a vSAN based book through VMware Press. The book was titled vSAN Essentials. As mentioned before, after restructuring and rewriting a lot of the content we felt that the title of the book didn’t match the content, so we decided to rebrand it to vSAN 6.7 U1 Deep Dive. After receiving very thorough reviews by Frank Denneman and Pete Koehler (Thanks guys!) we managed to complete it this week after we added a great foreword by our business unit’s SVP and General Manager, Yanbing Li.
Cormac and I decided to take the self-publishing route for this book, which allows us to set a great price for the ebook and enable the Amazon matchbook option, giving everyone who buys the paper version through Amazon the option to buy the e-book with a nice discount! As prices will vary based on location I am only going to list the USD prices. Please check your local Amazon website for localized prices. Oh, and before I forget, I would like to recommend buying the ebook flavor! Why? Well:
“On average, each printed book releases 8.85 pounds of carbon dioxide into the environment. Together, the newspaper and book-printing industries cut down 125 million trees per year and emit 44 million tons of CO2.”
We appreciate all support, but we prefer the cleanest option from an environmental stance, this is also the reason we priced the ebook a lot cheaper than the paper version. Anyway, here are the links to the US store, we hope you enjoy the content, and of course as always an Amazon review would be appreciated! Interestingly, it seems we already reached number 1 in the category Virtualization and the category Storage before this announcement, thanks everyone, we really appreciate it! (Please note, as an Amazon Associate I earn from below qualifying purchases.)
- Paper version – 39.95 USD
- Ebook version – 9.99 USD
- Match book price – 2.99 USD for the ebook!
(you need to buy the paper edition first before you see this discount, and this may not be available in all regions, unfortunately.)

UPDATE:
It appears that some Amazon stores take a bit longer to index the content, so listing all the different versions below for the different stores that sell it:


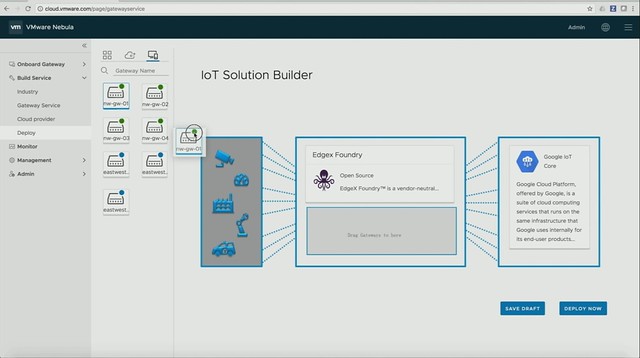
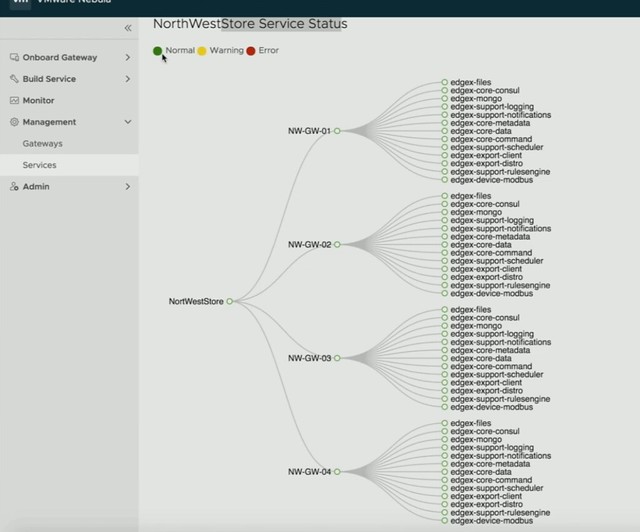
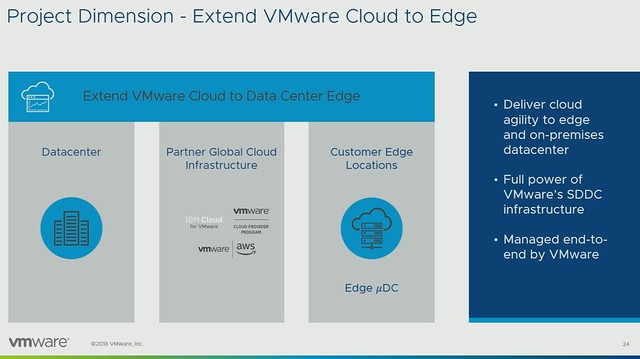
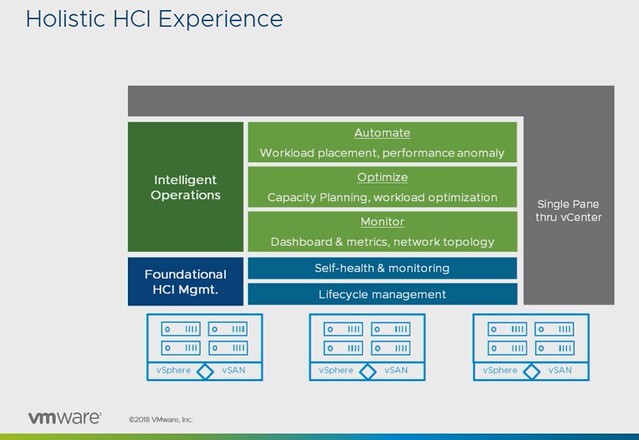
 Michael started out with an explanation about what an SSDC brings to customers, and how a digital foundation is crucial for any organization that wants to be competitive in the market. vSAN, of course, is a big part of the digital foundation, and for almost every customer data protection and data recovery is crucial. Michael went over the various vSAN use cases and also the availability and recoverability mechanisms before introducing Native vSAN Data Protection.
Michael started out with an explanation about what an SSDC brings to customers, and how a digital foundation is crucial for any organization that wants to be competitive in the market. vSAN, of course, is a big part of the digital foundation, and for almost every customer data protection and data recovery is crucial. Michael went over the various vSAN use cases and also the availability and recoverability mechanisms before introducing Native vSAN Data Protection.