There was a great article by Cormac talking about vSAN File Services published last week. I had some articles planned, but hadn’t started yet, so when I saw the article I figured I would do something different. No point in rehashing what Cormac has already shared right. I figured I would shoot another demo, and do a brief write-up so people know what vSAN File Services is all about. In vSAN/vSphere 7.0 there’s now a new feature, and this is vSAN File Service. vSAN File Services can simply be enabled on a cluster level and provides you NFS 3 and 4.1 capabilities. The great thing about the solution is that you can create file shares and associate policies with the file shares. In other words, you can have a file share with RAID-1, RAID-5, or maybe even striping or stretched across locations when that is supported.

When you enable File Service, vSAN will deploy a number of “agent VMs” and these VMs/appliances are fully managed by vSAN. These agent VMs run Photon OS and have the file service capabilities enabled through docker/container technology. After these File Service Agent VMs have been deployed, the docker container instances have been instantiated and configured, vSAN File Service will be up and running and available for use. Next, you could simply create a file share and start consuming it. But before I reveal everything, let’s just head over to the demo below. I hope you enjoy it!




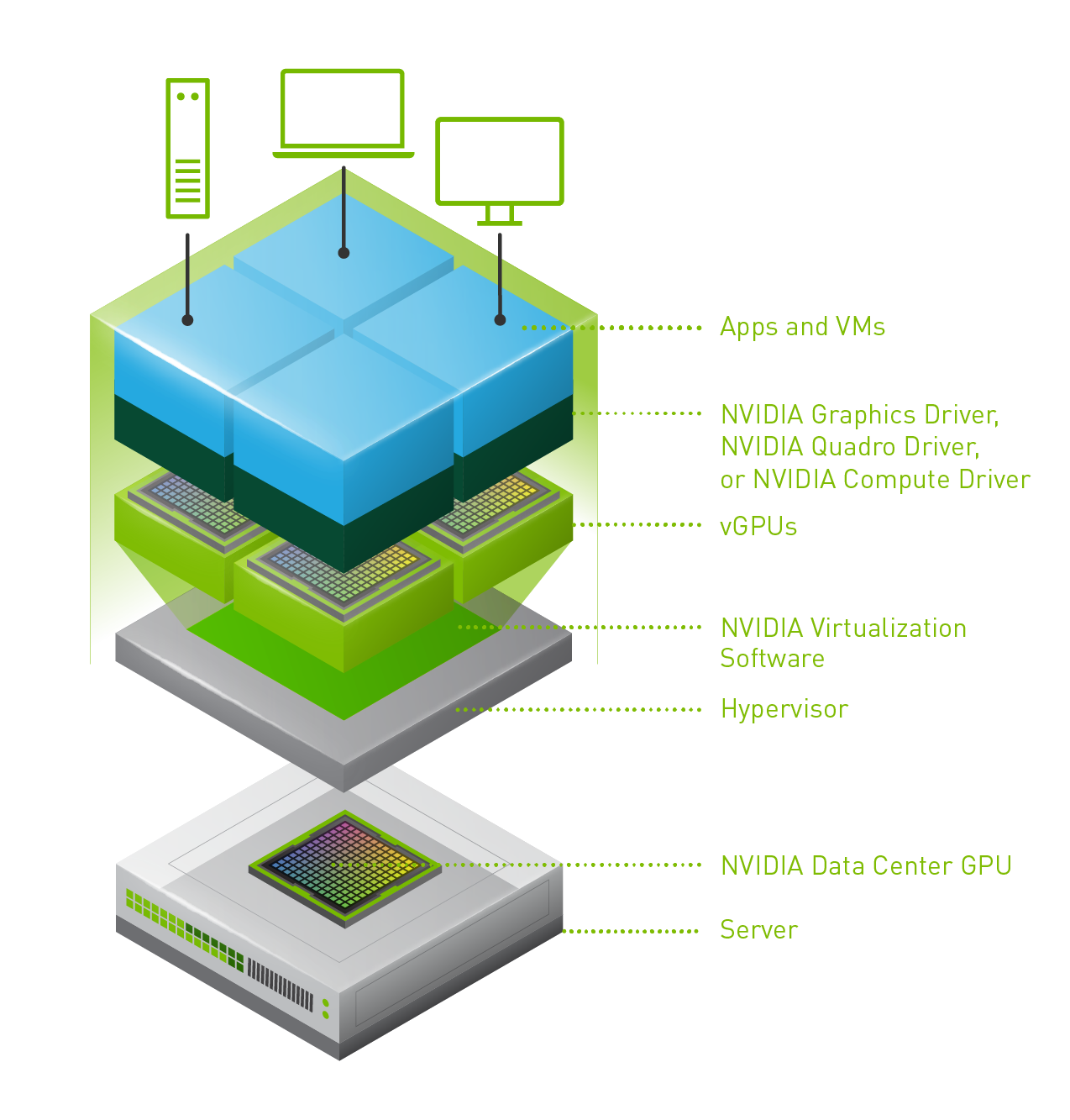 Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in
Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in