I recorded a webinar a while back. It was streamed last week, and I figured that as I have the recording here, I may as well share it with you. In this webinar I discuss many of the new features which were introduced as part of vSAN 7.0 U1, features like HCI Mesh, IO Insight, enhanced File Service capabilities, and much more. The session is about 40 minutes long, but of course, the great thing about youtube is that you can play it at a different speed. Hope you will enjoy it! Click on the video below, or simply follow this link to youtube. Make sure to like the video, and subscribe to my channel as well!
VMware
vCLS VMs not powering on, insufficient resources error
This week I had someone internally me asking about a situation where vCLS VMs (learn more about vSphere Cluster Service here.) were not powering on and an error was thrown stating “insufficient resources”. I had seen this issue before at some point and I knew it had something to do with the VM version and EVC. The details of the error messages seem to support that. The UI showed the following on the “power on virtual machine” task:
Insufficient resources
And then when you would look at the details of the error you could see the following:
The target host does not support the virtual machine's current hardware requirements.
Or you could see:
Feature 'MWAIT' was absent, but must be present.

So how do you solve this problem? First of all, this could be two different problems. We solved it the following way, please note that the second option was just us fiddling around to get the VMs provisioned and powered-on, and this is not the official VMware procedure to get it working. I have reported this to the engineers to figure out why this happens, and to get it fixed. There are two options, please use Option 1, as this is a requirement for EVC and the recommended method when you see the “MWAIT” error:
Option 1:
Verify if “Monitor/MWAIT” is set to Enabled in the BIOS. If it is set to Disabled, then this is why the power-on fails. vCLS has per-VM EVC enabled on the VM.
If you can’t enable Monitor/MWAIT, then below is the procedure for disabling “per VM EVC” for the provisioned vCLS VMs.
Option 2:
- Upgrade the VM’s “Compatibility” version to at least “VM version 14” (right-click the VM)
- Click on the VM, click on the Configure tab and click on “VMware EVC”
- Click on “Edit” and click on “Yes” when you are informed to not make changes to the VM
- Disable “EVC”
- Repeat for the other vCLS VMs
I want to mention cosmin.gq, as it seems the issue (and resolution with regards to disabling EVC) was also reported on that blog, and considering they reported it in October already it only seems fair to mention them here also.
vSphere HA reporting not enough failover resources fault with stretched cluster failure scenario
Last few months I had a couple of customers asking why vSphere HA was reporting “not enough failover resources” fault in a stretched cluster failure scenario for virtual machines that are still up and running. Now before I explain why, let’s paint a picture first to make it clear what is happening here. When you run a stretched cluster you can have a scenario where a particular VM (or multiple VMs) are not mirrored/replicated across locations. Now note, with vSAN you can specify for any given VM on a VM level how and if the VM should be available across locations. Typically you would see a VM with RAID-1 across locations, and then RAID-1/5/6 within a location. However, you can also have a scenario where a VM is not replicated across locations, but from a storage point of view only available within a location, this is depicted in the diagram below.
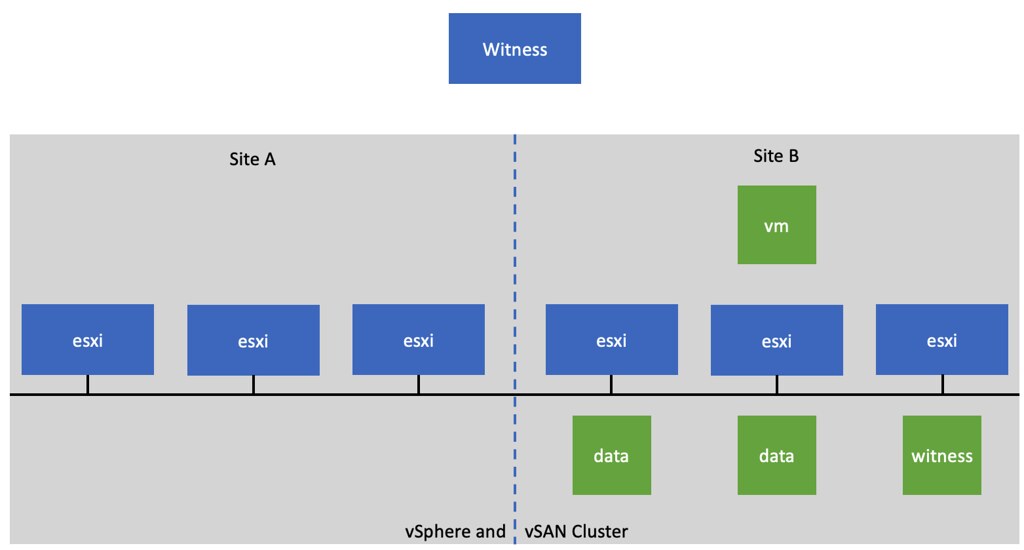
Now in this scenario, when Site A is somehow partitioned from Site B, you will see alarms/errors which indicate that vSphere HA has tried to restart the VM that is located in Site B in Site A and that is has failed as a result of not having enough failover resources.
This, of course, is not the result of not having sufficient failover resources, but it is the result of the fact that Site A does not have access to the required storage components to restart the VM. Basically what HA is reporting is that it doesn’t have the resources which have the ability to restart the impacted VM(s).
Now, if you have paid attention, you will probably wonder why HA tries to restart the VM in the first place, as the VM will still be running in this scenario. Why is it still running? Well the VM isn’t stretched, and this is a partition and not an isolation, which means the isolation response doesn’t kill the VM. So why restart it? Well, as Site A is partitioned from Site B, Site A does not know what the status is of Site B. Site A only knows that Site B is not responding at all, and the only thing it can do is assume the full site has failed. As a result it will attempt a failover for all VMs that were/are running in Site B and were protected by vSphere HA.
Hope that explains why this happens. If you are not sure you understand the full scenario, I recorded a quick five minute video actually walking through the scenario and explaining what happens. You can watch that below, or simply go to youtube.
How to login to the vCLS VMs!?
I was asked this question this week, how you can login to the vCLS VMs. Now before I share the video, I want to mention that I do not encourage people doing this, but as it is documented and supported I do want to provide a simple “how to” for how this works. If you want to login to the vCLS VM, maybe for troubleshooting if needed or for auditing, you can do so by SSH’ing first into your vCenter Server. When logged in to the vCenter Server you run the following command, which then returns the password, this will then allow you to login to the console of the vCLS VM. Again, I do not want to encourage you to do this. Either way, below you find the command for retrieving the password, and a short demo of me retrieving the password and logging in.
/usr/lib/vmware-wcp/decrypt_clustervm_pw.py
Did you know vSphere 7.0 Update 1 also has a Skyline Health Check for vSphere Clustering Services?
I did not know this, but yesterday the PM for vCLS reached out to me and informed me that we now have a Skyline Health Check as well for vSphere Clustering Services. The funny thing is that I actually requested this health check to be added after having a discussion on the topic of vCLS with the PM. Very impressive how fast the engineering team managed to include an additional health check for a brand new feature, this close to the release. I created a short demo, which shows you where you can find the vSphere Skyline Health option in the vSphere Client, and of course, it shows the vCLS Health Check being triggered. If you see the health check triggered, you can as mentioned enable retread mode and disable it again, this will provision a fresh set of vCLS VMs. How you do this you can find in this “considerations blog“, or simply watch the demo I shared here.