Last few months I had a couple of customers asking why vSphere HA was reporting “not enough failover resources” fault in a stretched cluster failure scenario for virtual machines that are still up and running. Now before I explain why, let’s paint a picture first to make it clear what is happening here. When you run a stretched cluster you can have a scenario where a particular VM (or multiple VMs) are not mirrored/replicated across locations. Now note, with vSAN you can specify for any given VM on a VM level how and if the VM should be available across locations. Typically you would see a VM with RAID-1 across locations, and then RAID-1/5/6 within a location. However, you can also have a scenario where a VM is not replicated across locations, but from a storage point of view only available within a location, this is depicted in the diagram below.
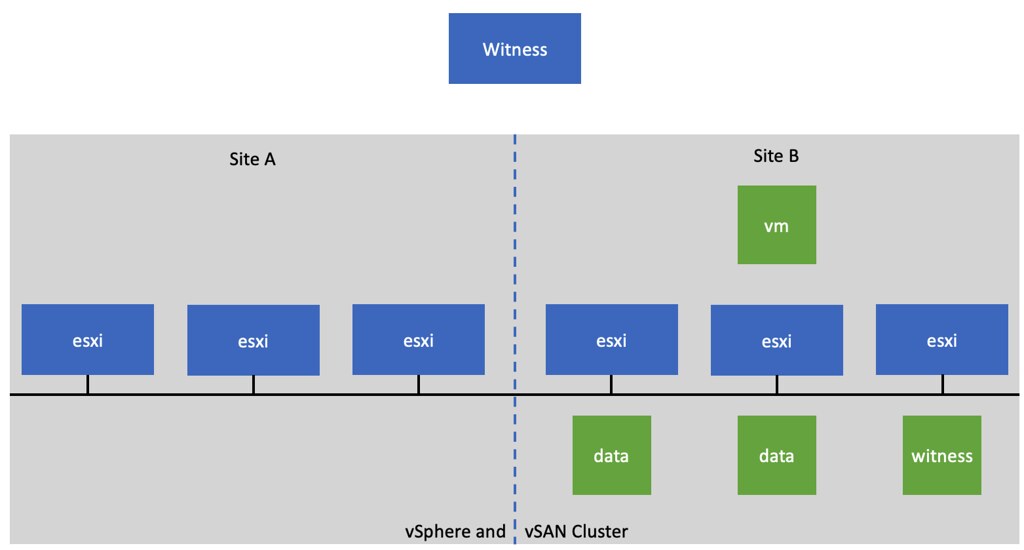
Now in this scenario, when Site A is somehow partitioned from Site B, you will see alarms/errors which indicate that vSphere HA has tried to restart the VM that is located in Site B in Site A and that is has failed as a result of not having enough failover resources.
This, of course, is not the result of not having sufficient failover resources, but it is the result of the fact that Site A does not have access to the required storage components to restart the VM. Basically what HA is reporting is that it doesn’t have the resources which have the ability to restart the impacted VM(s).
Now, if you have paid attention, you will probably wonder why HA tries to restart the VM in the first place, as the VM will still be running in this scenario. Why is it still running? Well the VM isn’t stretched, and this is a partition and not an isolation, which means the isolation response doesn’t kill the VM. So why restart it? Well, as Site A is partitioned from Site B, Site A does not know what the status is of Site B. Site A only knows that Site B is not responding at all, and the only thing it can do is assume the full site has failed. As a result it will attempt a failover for all VMs that were/are running in Site B and were protected by vSphere HA.
Hope that explains why this happens. If you are not sure you understand the full scenario, I recorded a quick five minute video actually walking through the scenario and explaining what happens. You can watch that below, or simply go to youtube.