It was a busy week at VMware Explore last week, but we still managed to record new content to discuss what was happening at VMware Explore. We spoke with folks like Kit Colbert, Chris Wolf, Dave Morera, Sazzala Reddy, and many others. We also recorded episodes to cover the vSAN 8.0 and vSphere 8.0 release. For vSAN 8.0 we asked Pete Koehler to go over all the changes with vSAN Express Storage Architecture. vSphere 8.0 was covered by Feidhlim O’Leary, going into every aspect of the release, and it is a lot.
VMware
Introducing vSphere 8!
This is the moment you all have been waiting for, vSphere 8.0 was just announced. There are some great new features and capabilities in this release, and in this blog post I am going to be discussing some of these.
First of all, vSphere Distributed Services Engine. What is this? Well basically it is Project Monterey. For those who have no idea what Project Monterey is, it is VMware’s story around SmartNICs or Data Processing Units (DPUs) as they are typically called. These devices are basically NICs on steroids, NICs with a lot more CPU power, memory capacity, and bandwidth/throughput. These devices not only enable you to push more packets and do it faster, they also provide the ability to run services directly on these cards.
Services? Yes, with these devices you can for instance offload NSX services from the CPU to the DPU. This not only brings NSX to the layer where it belongs, the NIC, it also frees up x86 cycles. Note, that in vSphere 8 it means that an additional instance of ESXi is installed on the DPU itself. This instance is managed by vCenter Server, just like your normal hosts, and it is updated/upgraded using vLCM. In other words, from an operational perspective, most will be familiarized fast. Now having said that, in this first release, the focus very much is on acceleration, not as much on services.
The next major item is Tanzu Kubernetes Grid 2.0. I am not the expert on this, Cormac Hogan is, so I want to point everyone to his blog. What for me probably is the major feature that this version brings is Workload Availability Zones. It is a feature that Frank, Cormac, and I were involved in during the design discussions a while back, and it is great to finally see it being released. Workload Availability Zones basically enable you to deploy a Tanzu Kubernetes Cluster across vSphere Clusters. As you can imagine this enhances resiliency of your deployment, the diagram below demonstrates this.

For Lifecycle Management also various things were introduced. I already mentioned the vLCM now support DPUs, which is great as it will make managing these new entities in your environment so much easier. vLCM now also can manage Stand Alone Host’s via the API, and vLCM can remediate hosts placed into maintenance mode manually now as well. Why is this important? Well this will help customers who want to remediate hosts in parallel to decrease the maintenance window. For vCenter Server lifecycle management, there also was a major improvement. vSphere 8.0 now has the ability to store the vCenter Server cluster state in a distributed key-value store running on the ESXi hosts in the cluster. Why would it do this? Well it basically provides the ability to roll back to the last known state since the last backup. In other words, if you added a host to the cluster after the last backup, this is now stored in the distributed key-value store. When a backup is then restored after a failure, vCenter and the distributed key-value store will then sync so that the last known state is restored.
Last lifecycle management-related feature I want to discuss is vSphere Configuration Profiles. vSphere Configuration Profiles is a feature that is released as Tech Preview and over time will replace Host Profiles. vSphere Configuration Profiles introduces the “desired-state” model to host configuration, just like vLCM did for host updates and upgrades. You define the desired state, you attach it to a cluster and it will be applied. Of course, the current state and desired state will be monitored to prevent configuration drift from occurring. If you ask me, this is long overdue and I hope many of you are willing to test this feature and provide feedback so that it can be officially supported soon.
For AI and ML workload a feature is introduced which enables you to create Device Groups. What does this mean? It basically enables you to logically link two devices (NIC and GPU, or GPU and GPU) together. This is typically done with devices that are either linked (GPUs for instance through something like NVIDIA NVLINK) or a GPU and a NIC which are tightly coupled as they are on the same PCIe Switch connected to the same CPU, bundling these and exposing them as a pair to a VM (through Assignable Hardware) with an AI/ML workload simply optimizes the communication/IO as you avoid the hop across the interconnect as shown in the below diagram.

On top of the above firework, there are also many new smaller enhancements. Virtual Hardware version 20 for instance is introduced, and this enables you to manage your vNUMA configuration via the UI instead of via advanced settings. Also, full support for Windows 11 at scale is introduced by providing the ability to automatically replace the required vTPM device when a Windows 11 VM is cloned, ensuring that each VM has a unique vTPM device.
There’s more, and I would like to encourage you to read the material on core.vmware.com/vsphere, and for TKG read Cormac’s material! I also highly recommend this post about what is new for core storage.
Introducing vSAN 8 – Express Storage Architecture (ESA)
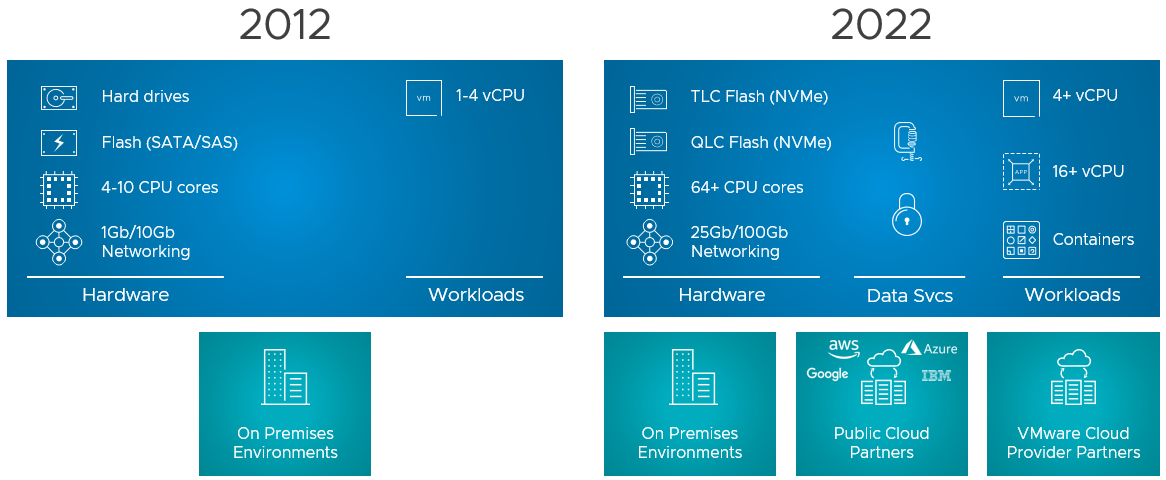
I debated whether I would write this blog now or wait a few weeks, as I know that the internet will be flooded with articles. But as it helps me as well to write down these things, I figured why not. So what is this new version of vSAN? vSAN Express Storage Architecture (vSAN ESA) introduces a new architecture for vSAN specifically with vSAN 8.0. This new architecture was developed to cater to this wave of new flash devices that we have seen over the past years, and we expect to see in the upcoming years. Not just storage, it also takes the huge improvements in terms of networking throughput and bandwidth into consideration. On top of that, we’ve also seen huge increases in available CPU and Memory capacity, hence it was time for a change.
Does that mean the “original” architecture is gone? No, vSAN Original Storage Architecture (OSA) still exists today and will exist for the foreseeable future. VMware understands that customers have made significant investments, so it will not disappear. Also, vSAN 8 brings fixes and new functionality for users of the current vSAN architecture (the logical cache capacity has been increased to 1.6TB instead of 600GB for instance.) VMware also understands that not every customer is ready to adopt this “single tier architecture”, which is what vSAN ESA delivers in the first release, but mind that this architecture also caters to other implementations (two-tier) in the future. What does this mean? When you create a vSAN cluster, you get to pick the architecture that you want to deploy for that environment (ESA or OSA), it is that simple! And of course, you do that based on the type of devices you have available. Or even better, you look at the requirements of your apps and you base your decision of OSA vs ESA and the type of hardware you need on those requirements. Again, to reiterate, vSAN Express Storage Architecture provides a flexible architecture that will use a single tier in vSAN 8 taking modern-day hardware (and future innovations) into consideration.
Before we look at the architecture, why would a customer care, what does vSAN ESA bring?
- Simplified storage device provisioning
- Lower CPU usage per processed IO
- Adaptive RAID-5 and RAID-6 at the performance of RAID-1
- Up to 4x better data compression
- Snapshots with minimal performance impact
When you create a vSAN ESA cluster the first thing that probably stands out is that you no longer need to create disk groups, which speaks to the “Simplified storage device provisioning” bullet point. With the OSA implementation, you create a disk group with a caching device and capacity devices, but with ESA that is no longer needed. This is the first thing I noticed. You now simply select all devices and they will be part of your vSAN datastore. It doesn’t mean though that there’s no caching mechanism, but it just has been implemented differently. With vSAN ESA, all devices contribute to capacity and all devices contribute to performance. It has the added benefit that if one device fails that it doesn’t impact anything else but what is stored on that device. With OSA, of course, it could impact the whole disk group that the device belonged to.
So now that we know that we no longer have disk groups with caching disks, how do we ensure we still get the performance customers expect? Well, there were a couple of things that were introduced that helped with that. First of all, a new log-structured file system was introduced. This file system helps with coalescing writes and enables fast acknowledgments of the IOs. This new layer will also enable direct compression of the data (enabled by default, and can be disabled via policy) and packaging of full stripes for the capacity “leg”. Capacity what? Yes, this is a big change that is introduced as well. With vSAN ESA you have a capacity leg and a performance leg. Let me show you what that looks like, and kudos to Pete Koehler for the great diagram!
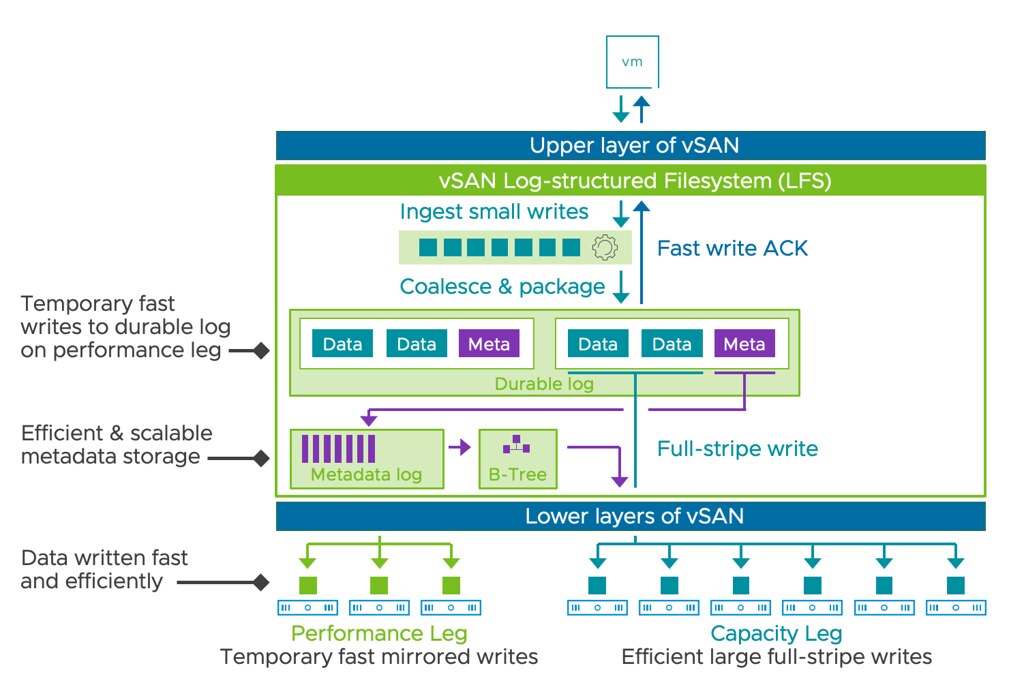
As the above diagram indicates, you have a performance leg which is RAID-1 and then there’s a capacity leg which can be RAID-1 but will typically be RAID-5 or RAID-6. Depending on the size of your cluster of course. Another thing that will depend on the size of the cluster, this the size of your RAID-5 configuration, that is where the adaptable RAID-5 comes into play. It is an interesting solution, and it enables customers to use RAID-5 implementations starting with only 3 hosts all the way up to 6 hosts or more. If you have 3-5 hosts then you will get a 2+1 configuration, meaning 2 components for data and 1 for parity. When you have 6 hosts or larger you will get a 4+1 configuration. This is different from the original implementation as there you would always get 3+1. For RAID-6 the implementation is 4+2 by the way.
I’ve already briefly mentioned it, but compression is now enabled by default. The reason for it is that the cost of compression is really low with the current implementation as compression happens all the way at the top. That means that when a write is performed the blocks actually are sent over the network compressed as well to their destination and they are stored immediately. So no need to unpack and compress again. The other interesting thing is that the implementation of compression has also changed, leading to an improved efficiency that can go up to an 8:1 data reduction. The same applies to encryption implementation, it also happens at the top, so you get data-at-rest and data-in-transit encryption automatically when it is enabled. Enabling encryption still happens at the cluster level though, where compression can now be enabled/disabled on a per VM basis.
Another big change is the snapshot implementation. We’ve seen a few changes in snapshot implementation over the years, but this one is a major change. I guess the big change is that when you create a snapshot vSAN does not create a separate object. This means that the snapshot basically exists within the current object layout. Big benefit, of course, being that the object count doesn’t skyrocket when you create many snapshots, another added benefit is the performance of this implementation. Consolidation of a snapshot for instance when tested went 100x faster, this means much lower stun times, which I know everyone can appreciate. Not only is it much much faster to consolidate, but also normal IO is much faster during consolidation and during snapshot creation. I love it!
The last thing I want to mention is that from a networking perspective vSAN ESA not only performs much better, but it also is much more efficient. Allowing for ever faster resyncs, and faster virtual machine I/O. On top of that, because compression has been implemented the way it has been implemented it simply also means there’s more bandwidth remaining.
For those who prefer to hear the vSAN 8 ESA story through a podcast, make sure to check the Unexplored Territory Podcast next week, as we will have Pete Koehler answering all questions about vSAN ESA. Also, on core.vmware.com you will find ALL details of this new architecture in the upcoming weeks, and also make sure to read this official blog post on vmware.com.
Unexplored Territory #023 – Introducing Oracle Cloud VMware Solution with Richard Garsthagen
Although it is the summer holiday season in Europe, we don’t take a break when it comes to releasing new podcast content. This episode features one of the first VMware bloggers ever (maybe the first!?), who now is responsible for Cloud at Oracle, Richard Garsthagen. Richard introduced us to the world of Oracle Cloud VMware Solution. Very interesting stuff if you ask me, and with some unique capabilities compared to other public cloud offerings. (Especially from an operational point of view!) Listen now on Spotify (https://spoti.fi/3bB5QXE), Apple (https://apple.co/3SCPoa2), or anywhere else you get your podcasts! Or simply use the player below.
Nested Fault Domains on a 2-Node vSAN Stretched Cluster, is it supported?
I spotted a question this week on VMTN, the question was fairly basic, are nested fault domains supported on a 2-node vSAN Stretched Cluster? It sounds basic, but unfortunately, it is not documented anywhere, probably because stretched 2-node configurations are not very common. For those who don’t know, with a nested fault domain on a two-node cluster you basically provide an additional layer of resiliency by replicating an object within a host as well. A VM Storage Policy for a configuration like that will look as follows.

This however does mean that you would need to have a minimum of 3 fault domains within your host as well if you want to, this means that you will need to have a minimum of 3 disk groups in each of the two hosts as well. Or better said, when you configure Host Mirroring and then select the second option failures to tolerate the following list will show you the number of disk groups per host you need at a minimum:
- Host Mirroring – 2 Node Cluster
- No Data Redundancy – 1 disk group
- 1 Failure – RAID1 – 3 disk groups
- 1 Failure – RAID5 – 4 disk groups
- 2 Failures – RAID1 – 5 disk groups
- 2 Failures – RAID6 – 6 disk groups
- 3 Failures – RAID1 – 7 disk groups
If you look at the list, you can imagine that if you need additional resiliency it will definitely come at a cost. But anyway, back to the question, is it supported when your 2-node configuration happens to be stretched across locations, and the answer is yes, VMware supports this.